Содержание
- B.1. MySQL 5.5 FAQ: General
- B.2. MySQL 5.5 FAQ: Storage Engines
- B.3. MySQL 5.5 FAQ: Server SQL Mode
- B.4. MySQL 5.5 FAQ: Stored Procedures and Functions
- B.5. MySQL 5.5 FAQ: Triggers
- B.6. MySQL 5.5 FAQ: Views
- B.7. MySQL 5.5 FAQ:
INFORMATION_SCHEMA - B.8. MySQL 5.5 FAQ: Migration
- B.9. MySQL 5.5 FAQ: Security
- B.10. MySQL FAQ: MySQL 5.5 and MySQL Cluster
- B.11. MySQL 5.5 FAQ: MySQL Chinese, Japanese, and Korean Character Sets
- B.12. MySQL 5.5 FAQ: Connectors & APIs
- B.13. MySQL 5.5 FAQ: Replication
- B.14. MySQL 5.5 FAQ: MySQL, DRBD, and Heartbeat
- B.14.1. Distributed Replicated Block Device (DRBD)
- B.14.2. Linux Heartbeat
- B.14.3. DRBD Architecture
- B.14.4. DRBD and MySQL Replication
- B.14.5. DRBD and File Systems
- B.14.6. DRBD and LVM
- B.14.7. DRBD and Virtualization
- B.14.8. DRBD and Security
- B.14.9. DRBD and System Requirements
- B.14.10. DRBD and Support and Consulting
Questions
B.1.1: Which version of MySQL is production-ready (GA)?
B.1.2: What is the state of development (non-GA) versions?
B.1.3: Can MySQL 5.5 do subqueries?
B.1.4: Can MySQL 5.5 perform multiple-table inserts, updates, and deletes?
B.1.5: Does MySQL 5.5 have a Query Cache? Does it work on Server, Instance or Database?
B.1.6: Does MySQL 5.5 have Sequences?
B.1.7: Does MySQL 5.5 have a
NOW()function with fractions of seconds?B.1.8: Does MySQL 5.5 work with multi-core processors?
B.1.9: Why do I see multiple processes for
mysqld?B.1.10: Have there been there any improvements in error reporting when foreign keys fail? Does MySQL now report which column and reference failed?
B.1.11: Can MySQL 5.5 perform ACID transactions?
Questions and Answers
B.1.1: Which version of MySQL is production-ready (GA)?
At the time of writing this (December 2011), MySQL 5.5, MySQL 5.1, and MySQL 5.0 are supported for production use.
MySQL 5.5 achieved General Availability (GA) status with MySQL 5.5.8, which was released for production use on 3 December 2010.
MySQL 5.1 achieved General Availability (GA) status with MySQL 5.1.30, which was released for production use on 14 November 2008.
MySQL 5.0 achieved General Availability (GA) status with MySQL 5.0.15, which was released for production use on 19 October 2005. Note that active development for MySQL 5.0 has ended.
B.1.2: What is the state of development (non-GA) versions?
MySQL follows a milestone release model that introduces pre-production-quality features and stabilizes them to release quality (see http://forge.mysql.com/wiki/Development_Cycle). This process then repeats, so releases cycle between pre-production and release quality status. Please check the change logs to identify the status of a given release.
MySQL 5.4 was a development series. Work on this series has ceased.
MySQL 5.5 is being actively developed using the milestone release methodology described above.
MySQL 5.6 is being actively developed using the milestone release methodology described above.
MySQL 6.0 was a development series. Work on this series has ceased.
B.1.3: Can MySQL 5.5 do subqueries?
Yes. See Section 12.2.10, “Subquery Синтаксис”.
B.1.4: Can MySQL 5.5 perform multiple-table inserts, updates, and deletes?
Yes. For the syntax required to perform multiple-table updates,
see Section 12.2.11, “UPDATE Синтаксис”; for that required to perform
multiple-table deletes, see Section 12.2.2, “DELETE Синтаксис”.
A multiple-table insert can be accomplished using a trigger
whose FOR EACH ROW clause contains multiple
INSERT statements within a
BEGIN ... END block. See
Section 18.3, “Using Triggers”.
B.1.5: Does MySQL 5.5 have a Query Cache? Does it work on Server, Instance or Database?
Yes. The query cache operates on the server level, caching complete result sets matched with the original query string. If an exactly identical query is made (which often happens, particularly in web applications), no parsing or execution is necessary; the result is sent directly from the cache. Various tuning options are available. See Section 7.9.3, “The MySQL Query Cache”.
B.1.6: Does MySQL 5.5 have Sequences?
No. However, MySQL has an AUTO_INCREMENT
system, which in MySQL 5.5 can also handle inserts
in a multi-master replication setup. With the
auto_increment_increment and
auto_increment_offset system
variables, you can set each server to generate auto-increment
values that don't conflict with other servers. The
auto_increment_increment value
should be greater than the number of servers, and each server
should have a unique offset.
B.1.7:
Does MySQL 5.5 have a
NOW() function with fractions of
seconds?
No. This is on the MySQL roadmap as a “rolling feature”. This means that it is not a flagship feature, but will be implemented, development time permitting. Specific customer demand may change this scheduling.
However, MySQL does parse time strings with a fractional
component. See Section 10.3.2, “The TIME Type”.
B.1.8: Does MySQL 5.5 work with multi-core processors?
Yes. MySQL is fully multi-threaded, and will make use of multiple CPUs, provided that the operating system supports them.
B.1.9:
Why do I see multiple processes for mysqld?
When using LinuxThreads, you should see a minimum of three mysqld processes running. These are in fact threads. There is one thread for the LinuxThreads manager, one thread to handle connections, and one thread to handle alarms and signals.
B.1.10: Have there been there any improvements in error reporting when foreign keys fail? Does MySQL now report which column and reference failed?
The foreign key support in InnoDB has seen
improvements in each major version of MySQL. Foreign key support
generic to all storage engines is scheduled for MySQL 6.x; this
should resolve any inadequacies in the current storage engine
specific implementation.
B.1.11: Can MySQL 5.5 perform ACID transactions?
Yes. All current MySQL versions support transactions. The
InnoDB storage engine offers full ACID
transactions with row-level locking, multi-versioning,
nonlocking repeatable reads, and all four SQL standard isolation
levels.
The NDB storage engine supports the
READ COMMITTED transaction
isolation level only.
Questions
B.2.1: Where can I obtain complete documentation for MySQL storage engines?
B.2.2: Are there any new storage engines in MySQL 5.5?
B.2.3: Have any storage engines been removed in MySQL 5.5?
B.2.4: What are the unique benefits of the
ARCHIVEstorage engine?B.2.5: Do the new features in MySQL 5.5 apply to all storage engines?
Questions and Answers
B.2.1: Where can I obtain complete documentation for MySQL storage engines?
See Глава 13, Storage Engines. That chapter contains
information about all MySQL storage engines except for the
NDB storage engine used for MySQL
Cluster; NDB is covered in
Глава 16, MySQL Cluster NDB 7.2.
B.2.2: Are there any new storage engines in MySQL 5.5?
The features from the optional InnoDB Plugin
from MySQL 5.1 are folded into the built-in
InnoDB storage engine, so you can take
advantage of features such as the Barracuda file format,
InnoDB table compression, and the new
configuration options for performance. See
Section 13.4, “New Features of InnoDB 1.1” for details.
InnoDB also becomes the default storage
engine for new tables. See Section 13.3.1, “InnoDB as the Default MySQL Storage Engine”
for details.
B.2.3: Have any storage engines been removed in MySQL 5.5?
No.
B.2.4:
What are the unique benefits of the ARCHIVE
storage engine?
The ARCHIVE storage engine is ideally suited
for storing large amounts of data without indexes; it has a very
small footprint, and performs selects using table scans. See
Section 13.8, “The ARCHIVE Storage Engine”, for details.
B.2.5: Do the new features in MySQL 5.5 apply to all storage engines?
The general new features such as views, stored procedures,
triggers, INFORMATION_SCHEMA, precision math
(DECIMAL column type), and the
BIT column type, apply to all
storage engines. There are also additions and changes for
specific storage engines.
Questions
B.3.1: What are server SQL modes?
B.3.2: How many server SQL modes are there?
B.3.3: How do you determine the server SQL mode?
B.3.4: Is the mode dependent on the database or connection?
B.3.5: Can the rules for strict mode be extended?
B.3.6: Does strict mode impact performance?
B.3.7: What is the default server SQL mode when My SQL 5.5 is installed?
Questions and Answers
B.3.1: What are server SQL modes?
Server SQL modes define what SQL syntax MySQL should support and what kind of data validation checks it should perform. This makes it easier to use MySQL in different environments and to use MySQL together with other database servers. The MySQL Server apply these modes individually to different clients. For more information, see Section 5.1.6, “Server SQL Modes”.
B.3.2: How many server SQL modes are there?
Each mode can be independently switched on and off. See Section 5.1.6, “Server SQL Modes”, for a complete list of available modes.
B.3.3: How do you determine the server SQL mode?
You can set the default SQL mode (for mysqld
startup) with the --sql-mode
option. Using the statement
SET
[GLOBAL|SESSION]
sql_mode=', you can
change the settings from within a connection, either locally to
the connection, or to take effect globally. You can retrieve the
current mode by issuing a modes'SELECT @@sql_mode
statement.
B.3.4: Is the mode dependent on the database or connection?
A mode is not linked to a particular database. Modes can be set
locally to the session (connection), or globally for the server.
you can change these settings using
SET
[GLOBAL|SESSION]
sql_mode='.
modes'
B.3.5: Can the rules for strict mode be extended?
When we refer to strict mode, we mean a
mode where at least one of the modes
TRADITIONAL,
STRICT_TRANS_TABLES, or
STRICT_ALL_TABLES is enabled.
Options can be combined, so you can add restrictions to a mode.
See Section 5.1.6, “Server SQL Modes”, for more information.
B.3.6: Does strict mode impact performance?
The intensive validation of input data that some settings requires more time than if the validation is not done. While the performance impact is not that great, if you do not require such validation (perhaps your application already handles all of this), then MySQL gives you the option of leaving strict mode disabled. However—if you do require it—strict mode can provide such validation.
B.3.7: What is the default server SQL mode when My SQL 5.5 is installed?
By default, no special modes are enabled. See Section 5.1.6, “Server SQL Modes”, for information about all available modes and MySQL's default behavior.
Questions
B.4.1: Does MySQL 5.5 support stored procedures and functions?
B.4.2: Where can I find documentation for MySQL stored procedures and stored functions?
B.4.3: Is there a discussion forum for MySQL stored procedures?
B.4.4: Where can I find the ANSI SQL 2003 specification for stored procedures?
B.4.5: How do you manage stored routines?
B.4.6: Is there a way to view all stored procedures and stored functions in a given database?
B.4.7: Where are stored procedures stored?
B.4.8: Is it possible to group stored procedures or stored functions into packages?
B.4.9: Can a stored procedure call another stored procedure?
B.4.10: Can a stored procedure call a trigger?
B.4.11: Can a stored procedure access tables?
B.4.12: Do stored procedures have a statement for raising application errors?
B.4.13: Do stored procedures provide exception handling?
B.4.14: Can MySQL 5.5 stored routines return result sets?
B.4.15: Is
WITH RECOMPILEsupported for stored procedures?B.4.16: Is there a MySQL equivalent to using
mod_plsqlas a gateway on Apache to talk directly to a stored procedure in the database?B.4.17: Can I pass an array as input to a stored procedure?
B.4.18: Can I pass a cursor as an
INparameter to a stored procedure?B.4.19: Can I return a cursor as an
OUTparameter from a stored procedure?B.4.20: Can I print out a variable's value within a stored routine for debugging purposes?
B.4.21: Can I commit or roll back transactions inside a stored procedure?
B.4.22: Do MySQL 5.5 stored procedures and functions work with replication?
B.4.23: Are stored procedures and functions created on a master server replicated to a slave?
B.4.24: How are actions that take place inside stored procedures and functions replicated?
B.4.25: Are there special security requirements for using stored procedures and functions together with replication?
B.4.26: What limitations exist for replicating stored procedure and function actions?
B.4.27: Do the preceding limitations affect MySQL's ability to do point-in-time recovery?
B.4.28: What is being done to correct the aforementioned limitations?
Questions and Answers
B.4.1: Does MySQL 5.5 support stored procedures and functions?
Yes. MySQL 5.5 supports two types of stored routines—stored procedures and stored functions.
B.4.2: Where can I find documentation for MySQL stored procedures and stored functions?
See Section 18.2, “Using Stored Routines (Procedures and Functions)”.
B.4.3: Is there a discussion forum for MySQL stored procedures?
Yes. See http://forums.mysql.com/list.php?98.
B.4.4: Where can I find the ANSI SQL 2003 specification for stored procedures?
Unfortunately, the official specifications are not freely available (ANSI makes them available for purchase). However, there are books—such as SQL-99 Complete, Really by Peter Gulutzan and Trudy Pelzer—which give a comprehensive overview of the standard, including coverage of stored procedures.
B.4.5: How do you manage stored routines?
It is always good practice to use a clear naming scheme for your
stored routines. You can manage stored procedures with
CREATE [FUNCTION|PROCEDURE], ALTER
[FUNCTION|PROCEDURE], DROP
[FUNCTION|PROCEDURE], and SHOW CREATE
[FUNCTION|PROCEDURE]. You can obtain information about
existing stored procedures using the
ROUTINES table in the
INFORMATION_SCHEMA database (see
Section 19.18, “The INFORMATION_SCHEMA ROUTINES Table”).
B.4.6: Is there a way to view all stored procedures and stored functions in a given database?
Yes. For a database named dbname, use
this query on the
INFORMATION_SCHEMA.ROUTINES table:
SELECT ROUTINE_TYPE, ROUTINE_NAME
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_SCHEMA='dbname';
For more information, see Section 19.18, “The INFORMATION_SCHEMA ROUTINES Table”.
The body of a stored routine can be viewed using
SHOW CREATE FUNCTION (for a
stored function) or SHOW CREATE
PROCEDURE (for a stored procedure). See
Section 12.7.5.11, “SHOW CREATE PROCEDURE Синтаксис”, for more information.
B.4.7: Where are stored procedures stored?
In the proc table of the
mysql system database. However, you should
not access the tables in the system database directly. Instead,
use SHOW CREATE FUNCTION to
obtain information about stored functions, and
SHOW CREATE PROCEDURE to obtain
information about stored procedures. See
Section 12.7.5.11, “SHOW CREATE PROCEDURE Синтаксис”, for more information
about these statements.
You can also query the ROUTINES
table in the INFORMATION_SCHEMA
database—see Section 19.18, “The INFORMATION_SCHEMA ROUTINES Table”, for
information about this table.
B.4.8: Is it possible to group stored procedures or stored functions into packages?
No. This is not supported in MySQL 5.5.
B.4.9: Can a stored procedure call another stored procedure?
Yes.
B.4.10: Can a stored procedure call a trigger?
A stored procedure can execute an SQL statement, such as an
UPDATE, that causes a trigger to
activate.
B.4.11: Can a stored procedure access tables?
Yes. A stored procedure can access one or more tables as required.
B.4.12: Do stored procedures have a statement for raising application errors?
Yes. MySQL 5.5 implements the SQL standard
SIGNAL and RESIGNAL
statements. See Section 12.6.7, “Condition Handling”.
B.4.13: Do stored procedures provide exception handling?
MySQL implements HANDLER
definitions according to the SQL standard. See
Section 12.6.7.2, “DECLARE ...
HANDLER Синтаксис”, for details.
B.4.14: Can MySQL 5.5 stored routines return result sets?
Stored procedures can, but stored functions
cannot. If you perform an ordinary
SELECT inside a stored procedure,
the result set is returned directly to the client. You need to
use the MySQL 4.1 (or above) client/server protocol for this to
work. This means that—for instance—in PHP, you need
to use the mysqli extension rather than the
old mysql extension.
B.4.15:
Is WITH RECOMPILE supported for stored
procedures?
Not in MySQL 5.5.
B.4.16:
Is there a MySQL equivalent to using
mod_plsql as a gateway on Apache to talk
directly to a stored procedure in the database?
There is no equivalent in MySQL 5.5.
B.4.17: Can I pass an array as input to a stored procedure?
Not in MySQL 5.5.
B.4.18:
Can I pass a cursor as an IN parameter to a
stored procedure?
In MySQL 5.5, cursors are available inside stored procedures only.
B.4.19:
Can I return a cursor as an OUT parameter
from a stored procedure?
In MySQL 5.5, cursors are available inside stored
procedures only. However, if you do not open a cursor on a
SELECT, the result will be sent
directly to the client. You can also SELECT
INTO variables. See Section 12.2.9, “SELECT Синтаксис”.
B.4.20: Can I print out a variable's value within a stored routine for debugging purposes?
Yes, you can do this in a stored procedure,
but not in a stored function. If you perform an ordinary
SELECT inside a stored procedure,
the result set is returned directly to the client. You will need
to use the MySQL 4.1 (or above) client/server protocol for this
to work. This means that—for instance—in PHP, you
need to use the mysqli extension rather than
the old mysql extension.
B.4.21: Can I commit or roll back transactions inside a stored procedure?
Yes. However, you cannot perform transactional operations within a stored function.
B.4.22: Do MySQL 5.5 stored procedures and functions work with replication?
Yes, standard actions carried out in stored procedures and functions are replicated from a master MySQL server to a slave server. There are a few limitations that are described in detail in Section 18.7, “Binary Logging of Stored Programs”.
B.4.23: Are stored procedures and functions created on a master server replicated to a slave?
Yes, creation of stored procedures and functions carried out
through normal DDL statements on a master server are replicated
to a slave, so the objects will exist on both servers.
ALTER and DROP statements
for stored procedures and functions are also replicated.
B.4.24: How are actions that take place inside stored procedures and functions replicated?
MySQL records each DML event that occurs in a stored procedure and replicates those individual actions to a slave server. The actual calls made to execute stored procedures are not replicated.
Stored functions that change data are logged as function invocations, not as the DML events that occur inside each function.
B.4.25: Are there special security requirements for using stored procedures and functions together with replication?
Yes. Because a slave server has authority to execute any statement read from a master's binary log, special security constraints exist for using stored functions with replication. If replication or binary logging in general (for the purpose of point-in-time recovery) is active, then MySQL DBAs have two security options open to them:
Any user wishing to create stored functions must be granted the
SUPERprivilege.Alternatively, a DBA can set the
log_bin_trust_function_creatorssystem variable to 1, which enables anyone with the standardCREATE ROUTINEprivilege to create stored functions.
B.4.26: What limitations exist for replicating stored procedure and function actions?
Nondeterministic (random) or time-based actions embedded in
stored procedures may not replicate properly. By their very
nature, randomly produced results are not predictable and cannot
be exactly reproduced, and therefore, random actions replicated
to a slave will not mirror those performed on a master. Note
that declaring stored functions to be
DETERMINISTIC or setting the
log_bin_trust_function_creators
system variable to 0 will not allow random-valued operations to
be invoked.
In addition, time-based actions cannot be reproduced on a slave because the timing of such actions in a stored procedure is not reproducible through the binary log used for replication. It records only DML events and does not factor in timing constraints.
Finally, nontransactional tables for which errors occur during
large DML actions (such as bulk inserts) may experience
replication issues in that a master may be partially updated
from DML activity, but no updates are done to the slave because
of the errors that occurred. A workaround is for a function's
DML actions to be carried out with the IGNORE
keyword so that updates on the master that cause errors are
ignored and updates that do not cause errors are replicated to
the slave.
B.4.27: Do the preceding limitations affect MySQL's ability to do point-in-time recovery?
The same limitations that affect replication do affect point-in-time recovery.
B.4.28: What is being done to correct the aforementioned limitations?
You can choose either statement-based replication or row-based replication. The original replication implementation is based on statement-based binary logging. Row-based binary logging resolves the limitations mentioned earlier.
Mixed replication is also available (by
starting the server with
--binlog-format=mixed). This
hybrid, “smart” form of replication
“knows” whether statement-level replication can
safely be used, or row-level replication is required.
For additional information, see Section 15.1.2, “Replication Formats”.
Questions
B.5.1: Where can I find the documentation for MySQL 5.5 triggers?
B.5.2: Is there a discussion forum for MySQL Triggers?
B.5.3: Does MySQL 5.5 have statement-level or row-level triggers?
B.5.4: Are there any default triggers?
B.5.5: How are triggers managed in MySQL?
B.5.6: Is there a way to view all triggers in a given database?
B.5.7: Where are triggers stored?
B.5.8: Can a trigger call a stored procedure?
B.5.9: Can triggers access tables?
B.5.10: Can triggers call an external application through a UDF?
B.5.11: Is it possible for a trigger to update tables on a remote server?
B.5.12: Do triggers work with replication?
B.5.13: How are actions carried out through triggers on a master replicated to a slave?
Questions and Answers
B.5.1: Where can I find the documentation for MySQL 5.5 triggers?
See Section 18.3, “Using Triggers”.
B.5.2: Is there a discussion forum for MySQL Triggers?
Yes. It is available at http://forums.mysql.com/list.php?99.
B.5.3: Does MySQL 5.5 have statement-level or row-level triggers?
In MySQL 5.5, all triggers are FOR EACH
ROW—that is, the trigger is activated for each
row that is inserted, updated, or deleted. MySQL
5.5 does not support triggers using FOR
EACH STATEMENT.
B.5.4: Are there any default triggers?
Not explicitly. MySQL does have specific special behavior for
some TIMESTAMP columns, as well
as for columns which are defined using
AUTO_INCREMENT.
B.5.5: How are triggers managed in MySQL?
In MySQL 5.5, triggers can be created using the
CREATE TRIGGER statement, and
dropped using DROP TRIGGER. See
Section 12.1.19, “CREATE TRIGGER Синтаксис”, and
Section 12.1.30, “DROP TRIGGER Синтаксис”, for more about these statements.
Information about triggers can be obtained by querying the
INFORMATION_SCHEMA.TRIGGERS table.
See Section 19.26, “The INFORMATION_SCHEMA TRIGGERS Table”.
B.5.6: Is there a way to view all triggers in a given database?
Yes. You can obtain a listing of all triggers defined on
database dbname using a query on the
INFORMATION_SCHEMA.TRIGGERS table
such as the one shown here:
SELECT TRIGGER_NAME, EVENT_MANIPULATION, EVENT_OBJECT_TABLE, ACTION_STATEMENT
FROM INFORMATION_SCHEMA.TRIGGERS
WHERE TRIGGER_SCHEMA='dbname';
For more information about this table, see
Section 19.26, “The INFORMATION_SCHEMA TRIGGERS Table”.
You can also use the SHOW
TRIGGERS statement, which is specific to MySQL. See
Section 12.7.5.39, “SHOW TRIGGERS Синтаксис”.
B.5.7: Where are triggers stored?
Triggers for a table are currently stored in
.TRG files, with one such file one per
table.
B.5.8: Can a trigger call a stored procedure?
Yes.
B.5.9: Can triggers access tables?
A trigger can access both old and new data in its own table. A trigger can also affect other tables, but it is not permitted to modify a table that is already being used (for reading or writing) by the statement that invoked the function or trigger.
B.5.10: Can triggers call an external application through a UDF?
Yes. For example, a trigger could invoke the
sys_exec() UDF available at MySQL Forge here:
http://forge.mysql.com/projects/project.php?id=211
B.5.11: Is it possible for a trigger to update tables on a remote server?
Yes. A table on a remote server could be updated using the
FEDERATED storage engine. (See
Section 13.11, “The FEDERATED Storage Engine”).
B.5.12: Do triggers work with replication?
Yes. However, the way in which they work depends whether you are using MySQL's “classic” statement-based replication available in all versions of MySQL, or the row-based replication format introduced in MySQL 5.1.
When using statement-based replication, triggers on the slave are executed by statements that are executed on the master (and replicated to the slave).
When using row-based replication, triggers are not executed on the slave due to statements that were run on the master and then replicated to the slave. Instead, when using row-based replication, the changes caused by executing the trigger on the master are applied on the slave.
For more information, see Section 15.4.1.30, “Replication and Triggers”.
B.5.13: How are actions carried out through triggers on a master replicated to a slave?
Again, this depends on whether you are using statement-based or row-based replication.
Statement-based replication.
First, the triggers that exist on a master must be re-created
on the slave server. Once this is done, the replication flow
works as any other standard DML statement that participates in
replication. For example, consider a table
EMP that has an AFTER
insert trigger, which exists on a master MySQL server. The
same EMP table and AFTER
insert trigger exist on the slave server as well. The
replication flow would be:
Row-based replication. When you use row-based replication, the changes caused by executing the trigger on the master are applied on the slave. However, the triggers themselves are not actually executed on the slave under row-based replication. This is because, if both the master and the slave applied the changes from the master and—in addition—the trigger causing these changes were applied on the slave, the changes would in effect be applied twice on the slave, leading to different data on the master and the slave.
In most cases, the outcome is the same for both row-based and statement-based replication. However, if you use different triggers on the master and slave, you cannot use row-based replication. (This is because the row-based format replicates the changes made by triggers executing on the master to the slaves, rather than the statements that caused the triggers to execute, and the corresponding triggers on the slave are not executed.) Instead, any statements causing such triggers to be executed must be replicated using statement-based replication.
For more information, see Section 15.4.1.30, “Replication and Triggers”.
Questions
B.6.1: Where can I find documentation covering MySQL Views?
B.6.2: Is there a discussion forum for MySQL Views?
B.6.3: What happens to a view if an underlying table is dropped or renamed?
B.6.4: Does MySQL 5.5 have table snapshots?
B.6.5: Does MySQL 5.5 have materialized views?
B.6.6: Can you insert into views that are based on joins?
Questions and Answers
B.6.1: Where can I find documentation covering MySQL Views?
See Section 18.5, “Using Views”.
B.6.2: Is there a discussion forum for MySQL Views?
Yes. See http://forums.mysql.com/list.php?100
B.6.3: What happens to a view if an underlying table is dropped or renamed?
After a view has been created, it is possible to drop or alter a
table or view to which the definition refers. To check a view
definition for problems of this kind, use the
CHECK TABLE statement. (See
Section 12.7.2.2, “CHECK TABLE Синтаксис”.)
B.6.4: Does MySQL 5.5 have table snapshots?
No.
B.6.5: Does MySQL 5.5 have materialized views?
No.
B.6.6: Can you insert into views that are based on joins?
It is possible, provided that your
INSERT statement has a column
list that makes it clear there is only one table involved.
You cannot insert into multiple tables with a single insert on a view.
Questions
B.7.1: Where can I find documentation for the MySQL
INFORMATION_SCHEMAdatabase?B.7.2: Is there a discussion forum for
INFORMATION_SCHEMA?B.7.3: Where can I find the ANSI SQL 2003 specification for
INFORMATION_SCHEMA?B.7.4: What is the difference between the Oracle Data Dictionary and MySQL's
INFORMATION_SCHEMA?B.7.5: Can I add to or otherwise modify the tables found in the
INFORMATION_SCHEMAdatabase?
Questions and Answers
B.7.1:
Where can I find documentation for the MySQL
INFORMATION_SCHEMA database?
See Глава 19, INFORMATION_SCHEMA Tables
B.7.2:
Is there a discussion forum for
INFORMATION_SCHEMA?
See http://forums.mysql.com/list.php?101.
B.7.3:
Where can I find the ANSI SQL 2003 specification for
INFORMATION_SCHEMA?
Unfortunately, the official specifications are not freely
available. (ANSI makes them available for purchase.) However,
there are books available—such as SQL-99
Complete, Really by Peter Gulutzan and Trudy
Pelzer—which give a comprehensive overview of the
standard, including INFORMATION_SCHEMA.
B.7.4:
What is the difference between the Oracle Data Dictionary and
MySQL's INFORMATION_SCHEMA?
Both Oracle and MySQL provide metadata in tables. However,
Oracle and MySQL use different table names and column names.
MySQL's implementation is more similar to those found in DB2 and
SQL Server, which also support
INFORMATION_SCHEMA as defined in the SQL
standard.
B.7.5:
Can I add to or otherwise modify the tables found in the
INFORMATION_SCHEMA database?
No. Since applications may rely on a certain standard structure,
this should not be modified. For this reason, we
cannot support bugs or other issues which result from modifying
INFORMATION_SCHEMA tables or data.
Questions
Questions and Answers
B.8.1: Where can I find information on how to migrate from MySQL 5.1 to MySQL 5.5?
For detailed upgrade information, see Section 2.11.1, “Upgrading MySQL”. Do not skip a major version when upgrading, but rather complete the process in steps, upgrading from one major version to the next in each step. This may seem more complicated, but it will you save time and trouble—if you encounter problems during the upgrade, their origin will be easier to identify, either by you or—if you have a MySQL Enterprise subscription—by MySQL support.
B.8.2: How has storage engine (table type) support changed in MySQL 5.5 from previous versions?
Storage engine support has changed as follows:
Support for
ISAMtables was removed in MySQL 5.0 and you should now use theMyISAMstorage engine in place ofISAM. To convert a tabletblnamefromISAMtoMyISAM, simply issue a statement such as this one:ALTER TABLE
tblnameENGINE=MYISAM;Internal
RAIDforMyISAMtables was also removed in MySQL 5.0. This was formerly used to allow large tables in file systems that did not support file sizes greater than 2GB. All modern file systems allow for larger tables; in addition, there are now other solutions such asMERGEtables and views.The
VARCHARcolumn type now retains trailing spaces in all storage engines.MEMORYtables (formerly known asHEAPtables) can also containVARCHARcolumns.
Questions
B.9.1: Where can I find documentation that addresses security issues for MySQL?
B.9.2: Does MySQL 5.5 have native support for SSL?
B.9.3: Is SSL support be built into MySQL binaries, or must I recompile the binary myself to enable it?
B.9.4: Does MySQL 5.5 have built-in authentication against LDAP directories?
B.9.5: Does MySQL 5.5 include support for Roles Based Access Control (RBAC)?
Questions and Answers
B.9.1: Where can I find documentation that addresses security issues for MySQL?
The best place to start is Section 5.3, “General Security Issues”.
Other portions of the MySQL Documentation which you may find useful with regard to specific security concerns include the following:
B.9.2: Does MySQL 5.5 have native support for SSL?
Most 5.5 binaries have support for SSL connections between the client and server. We can't currently build with the new YaSSL library everywhere, as it is still quite new and does not compile on all platforms yet. See Section 5.5.8, “Using SSL for Secure Connections”.
You can also tunnel a connection using SSH, if (for example) the client application doesn't support SSL connections. For an example, see Section 5.5.9, “Connecting to MySQL Remotely from Windows with SSH”.
B.9.3: Is SSL support be built into MySQL binaries, or must I recompile the binary myself to enable it?
Most 5.5 binaries have SSL enabled for client/server connections that are secured, authenticated, or both. However, the YaSSL library currently does not compile on all platforms. See Section 5.5.8, “Using SSL for Secure Connections”, for a complete listing of supported and unsupported platforms.
B.9.4: Does MySQL 5.5 have built-in authentication against LDAP directories?
Not at this time.
B.9.5: Does MySQL 5.5 include support for Roles Based Access Control (RBAC)?
Not at this time.
In the following section, we answer questions that are frequently
asked about MySQL Cluster and the
NDBCLUSTER storage engine.
Questions
B.10.1: Which versions of the MySQL software support Cluster? Do I have to compile from source?
B.10.2: What do “NDB” and “NDBCLUSTER” mean?
B.10.3: What is the difference between using MySQL Cluster vs using MySQL Replication?
B.10.4: Do I need to do any special networking to run MySQL Cluster? How do computers in a cluster communicate?
B.10.5: How many computers do I need to run a MySQL Cluster, and why?
B.10.6: What do the different computers do in a MySQL Cluster?
B.10.7: When I run the
SHOWcommand in the MySQL Cluster management client, I see a line of output that looks like this:id=2 @10.100.10.32 (Version: 5.5.22, Nodegroup: 0, Master)
What is a “master node”, and what does it do? How do I configure a node so that it is the master?
B.10.8: With which operating systems can I use MySQL Cluster?
B.10.9: What are the hardware requirements for running MySQL Cluster?
B.10.10: How much RAM do I need to use MySQL Cluster? Is it possible to use disk memory at all?
B.10.11: What file systems can I use with MySQL Cluster? What about network file systems or network shares?
B.10.12: Can I run MySQL Cluster nodes inside virtual machines (such as those created by VMWare, Parallels, or Xen)?
B.10.13: I am trying to populate a MySQL Cluster database. The loading process terminates prematurely and I get an error message like this one:
ERROR 1114: The table 'my_cluster_table' is fullWhy is this happening?B.10.14: MySQL Cluster uses TCP/IP. Does this mean that I can run it over the Internet, with one or more nodes in remote locations?
B.10.15: Do I have to learn a new programming or query language to use MySQL Cluster?
B.10.16: How do I find out what an error or warning message means when using MySQL Cluster?
B.10.17: Is MySQL Cluster transaction-safe? What isolation levels are supported?
B.10.18: What storage engines are supported by MySQL Cluster?
B.10.19: In the event of a catastrophic failure—say, for instance, the whole city loses power and my UPS fails—would I lose all my data?
B.10.20: Is it possible to use
FULLTEXTindexes with MySQL Cluster?B.10.21: Can I run multiple nodes on a single computer?
B.10.22: Are there any limitations that I should be aware of when using MySQL Cluster?
B.10.23: How do I import an existing MySQL database into a MySQL Cluster?
B.10.24: How do MySQL Cluster nodes communicate with one another?
B.10.25: What is an arbitrator?
B.10.26: What data types are supported by MySQL Cluster?
B.10.27: How do I start and stop MySQL Cluster?
B.10.28: What happens to MySQL Cluster data when the MySQL Cluster is shut down?
B.10.29: Is it a good idea to have more than one management node for a MySQL Cluster?
B.10.30: Can I mix different kinds of hardware and operating systems in one MySQL Cluster?
B.10.31: Can I run two data nodes on a single host? Two SQL nodes?
B.10.32: Can I use host names with MySQL Cluster?
B.10.33: Does MySQL Cluster support IPv6?
B.10.34: How do I handle MySQL users in a MySQL Cluster having multiple MySQL servers?
B.10.35: How do I continue to send queries in the event that one of the SQL nodes fails?
B.10.36: How do I back up and restore a MySQL Cluster?
B.10.37: What is an “angel process”?
Questions and Answers
B.10.1: Which versions of the MySQL software support Cluster? Do I have to compile from source?
MySQL Cluster is not supported in standard MySQL Server 5.5 releases. Instead, MySQL Cluster is provided as a separate product. Currently, the following MySQL Cluster release series are available for production use:
MySQL Cluster NDB 6.3. This series is still maintained and available for use in production but is not recommended for new deployments. The most recent MySQL Cluster NDB 6.3 release can be obtained from
http://dev.mysql.com/downloads/cluster/.MySQL Cluster NDB 7.0. This series is Generally Available (GA) for use in production, although MySQL Cluster NDB 7.1 is recommended for new deployments. The most recent MySQL Cluster NDB 7.0 release can be obtained from http://dev.mysql.com/downloads/cluster/.
MySQL Cluster NDB 7.1. This series is the latest Generally Available (GA) version of MySQL Cluster. New deployments should use the latest release in this series. The most recent MySQL Cluster NDB 7.1 release can be obtained from http://dev.mysql.com/downloads/cluster/.
MySQL Cluster NDB 7.2.
This series is currently under development, and is based on
version 7.2 of the NDBCLUSTER
storage engine and MySQL Server 5.5. MySQL Cluster NDB 7.2 is
available for testing of new code and features but is not yet
recommended for use in production settings (where MySQL
Cluster NDB 7.1 should be used). The most recent MySQL Cluster
NDB 7.2 release can be obtained from
http://dev.mysql.com/downloads/cluster/.
You should use MySQL NDB Cluster NDB 7.0 or 7.1 for any new deployments; if you are using an older version of MySQL Cluster, you should upgrade to one of these soon as possible. For an overview of improvements made in MySQL Cluster NDB 7.0 and 7.1, see MySQL Cluster Development in MySQL Cluster NDB 7.0, and MySQL Cluster Development in MySQL Cluster NDB 7.1, respectively.
You can determine whether your MySQL Server has
NDBCLUSTER support using one of the
statements SHOW VARIABLES LIKE 'have_%',
SHOW ENGINES, or
SHOW PLUGINS.
B.10.2: What do “NDB” and “NDBCLUSTER” mean?
“NDB” stands for
“Network
Database”.
NDB and
NDBCLUSTER are both names for the
storage engine that enables clustering support in MySQL. While
our developers prefer NDB, either
name is correct; both names appear in our documentation, and
either name can be used in the ENGINE option
of a CREATE TABLE statement for
creating a MySQL Cluster table.
B.10.3: What is the difference between using MySQL Cluster vs using MySQL Replication?
In traditional MySQL replication, a master MySQL server updates
one or more slaves. Transactions are committed sequentially, and
a slow transaction can cause the slave to lag behind the master.
This means that if the master fails, it is possible that the
slave might not have recorded the last few transactions. If a
transaction-safe engine such as
InnoDB is being used, a transaction
will either be complete on the slave or not applied at all, but
replication does not guarantee that all data on the master and
the slave will be consistent at all times. In MySQL Cluster, all
data nodes are kept in synchrony, and a transaction committed by
any one data node is committed for all data nodes. In the event
of a data node failure, all remaining data nodes remain in a
consistent state.
In short, whereas standard MySQL replication is asynchronous, MySQL Cluster is synchronous.
Asynchronous replication for MySQL Cluster is available in MySQL 5.1 and later. MySQL Cluster Replication (also sometimes known as “geo-replication”) includes the capability to replicate both between two MySQL Clusters, and from a MySQL Cluster to a non-Cluster MySQL server. See Section 16.6, “MySQL Cluster Replication”.
B.10.4: Do I need to do any special networking to run MySQL Cluster? How do computers in a cluster communicate?
MySQL Cluster is intended to be used in a high-bandwidth environment, with computers connecting using TCP/IP. Its performance depends directly upon the connection speed between the cluster's computers. The minimum connectivity requirements for MySQL Cluster include a typical 100-megabit Ethernet network or the equivalent. We recommend you use gigabit Ethernet whenever available.
The faster SCI protocol is also supported, but requires special hardware. See Section 16.3.5, “Using High-Speed Interconnects with MySQL Cluster”, for more information about SCI.
B.10.5: How many computers do I need to run a MySQL Cluster, and why?
A minimum of three computers is required to run a viable cluster. However, the minimum recommended number of computers in a MySQL Cluster is four: one each to run the management and SQL nodes, and two computers to serve as data nodes. The purpose of the two data nodes is to provide redundancy; the management node must run on a separate machine to guarantee continued arbitration services in the event that one of the data nodes fails.
To provide increased throughput and high availability, you should use multiple SQL nodes (MySQL Servers connected to the cluster). It is also possible (although not strictly necessary) to run multiple management servers.
B.10.6: What do the different computers do in a MySQL Cluster?
A MySQL Cluster has both a physical and logical organization, with computers being the physical elements. The logical or functional elements of a cluster are referred to as nodes, and a computer housing a cluster node is sometimes referred to as a cluster host. There are three types of nodes, each corresponding to a specific role within the cluster. These are:
Management node. This node provides management services for the cluster as a whole, including startup, shutdown, backups, and configuration data for the other nodes. The management node server is implemented as the application ndb_mgmd; the management client used to control MySQL Cluster is ndb_mgm. See Section 16.4.4, “ndb_mgmd — The MySQL Cluster Management Server Daemon”, and Section 16.4.5, “ndb_mgm — The MySQL Cluster Management Client”, for information about these programs.
Data node. This type of node stores and replicates data. Data node functionality is handled by instances of the
NDBdata node process ndbd. For more information, see Section 16.4.2, “ndbd — The MySQL Cluster Data Node Daemon”.SQL node. This is simply an instance of MySQL Server (mysqld) that is built with support for the
NDBCLUSTERstorage engine and started with the --ndb-cluster option to enable the engine and the--ndb-connectstringoption to enable it to connect to a MySQL Cluster management server. For more about these options, see Section 16.3.4.2, “MySQL Server Options for MySQL Cluster”.ЗамечаниеAn API node is any application that makes direct use of Cluster data nodes for data storage and retrieval. An SQL node can thus be considered a type of API node that uses a MySQL Server to provide an SQL interface to the Cluster. You can write such applications (that do not depend on a MySQL Server) using the NDB API, which supplies a direct, object-oriented transaction and scanning interface to MySQL Cluster data; see MySQL Cluster API Overview: The NDB API, for more information.
B.10.7:
When I run the SHOW command in the MySQL
Cluster management client, I see a line of output that looks
like this:
id=2 @10.100.10.32 (Version: 5.5.22, Nodegroup: 0, Master)
What is a “master node”, and what does it do? How do I configure a node so that it is the master?
The simplest answer is, “It's not something you can control, and it's nothing that you need to worry about in any case, unless you're a software engineer writing or analyzing the MySQL Cluster source code”.
If you don't find that answer satisfactory, here's a longer and more technical version:
A number of mechanisms in MySQL Cluster require distributed coordination among the data nodes. These distributed algorithms and protocols include global checkpointing, DDL (schema) changes, and node restart handling. To make this coordination simpler, the data nodes “elect” one of their number to be a “master”. There is no user-facing mechanism for influencing this selection, which is is completely automatic; the fact that it is automatic is a key part of MySQL Cluster's internal architecture.
When a node acts as a master for any of these mechanisms, it is usually the point of coordination for the activity, and the other nodes act as “servants”, carrying out their parts of the activity as directed by the master. If the node acting as master fails, then the remaining nodes elect a new master. Tasks in progress that were being coordinated by the old master may either fail or be continued by the new master, depending on the actual mechanism involved.
It is possible for some of these different mechanisms and
protocols to have different master nodes, but in general the
same master is chosen for all of them. The node indicated as the
master in the output of SHOW in the
management client is actually the DICT master
(see The DBDICT Block, in
the MySQL Cluster API Developer Guide,
for more information), responsible for coordinating DDL and
metadata activity.
MySQL Cluster is designed in such a way that the choice of master has no discernable effect outside the cluster itself. For example, the current master does not have significantly higher CPU or resource usage than the other data nodes, and failure of the master should not have a significantly different impact on the cluster than the failure of any other data node.
B.10.8: With which operating systems can I use MySQL Cluster?
MySQL Cluster is supported on most Unix-like operating systems. MySQL Cluster NDB 7.2 is also supported in production settings on Microsoft Windows operating systems.
For more detailed information concerning the level of support
which is offered for MySQL Cluster on various operating system
versions, operating system distributions, and hardware
platforms, please refer to
http://www.mysql.com/support/supportedplatforms/cluster.html
.
B.10.9: What are the hardware requirements for running MySQL Cluster?
MySQL Cluster should run on any platform for which
NDB-enabled binaries are available.
For data nodes and API nodes, faster CPUs and more memory are
likely to improve performance, and 64-bit CPUs are likely to be
more effective than 32-bit processors. There must be sufficient
memory on machines used for data nodes to hold each node's share
of the database (see How much RAM do I
Need? for more information). For a computer which is
used only for running the MySQL Cluster management server, the
requirements are minimal; a common desktop PC (or the
equivalent) is generally sufficient for this task. Nodes can
communicate through the standard TCP/IP network and hardware.
They can also use the high-speed SCI protocol; however, special
networking hardware and software are required to use SCI (see
Section 16.3.5, “Using High-Speed Interconnects with MySQL Cluster”).
B.10.10: How much RAM do I need to use MySQL Cluster? Is it possible to use disk memory at all?
In MySQL 5.5, Cluster is in-memory only. This means that all table data (including indexes) is stored in RAM. Therefore, if your data takes up 1 GB of space and you want to replicate it once in the cluster, you need 2 GB of memory to do so (1 GB per replica). This is in addition to the memory required by the operating system and any applications running on the cluster computers.
If a data node's memory usage exceeds what is available in
RAM, then the system will attempt to use swap space up to the
limit set for DataMemory. However, this will
at best result in severely degraded performance, and may cause
the node to be dropped due to slow response time (missed
heartbeats). We do not recommend on relying on disk swapping in
a production environment for this reason. In any case, once the
DataMemory limit is reached, any operations
requiring additional memory (such as inserts) will fail.
We have implemented disk data storage for MySQL Cluster in MySQL 5.1 and later but we have no plans to add this capability in MySQL 5.5. See MySQL Cluster Disk Data Tables, for more information.
You can use the following formula for obtaining a rough estimate of how much RAM is needed for each data node in the cluster:
(SizeofDatabase × NumberOfReplicas × 1.1 ) / NumberOfDataNodes
To calculate the memory requirements more exactly requires determining, for each table in the cluster database, the storage space required per row (see Section 10.5, “Data Type Storage Requirements”, for details), and multiplying this by the number of rows. You must also remember to account for any column indexes as follows:
Each primary key or hash index created for an
NDBCLUSTERtable requires 21–25 bytes per record. These indexes useIndexMemory.Each ordered index requires 10 bytes storage per record, using
DataMemory.Creating a primary key or unique index also creates an ordered index, unless this index is created with
USING HASH. In other words:A primary key or unique index on a Cluster table normally takes up 31 to 35 bytes per record.
However, if the primary key or unique index is created with
USING HASH, then it requires only 21 to 25 bytes per record.
Note that creating MySQL Cluster tables with USING
HASH for all primary keys and unique indexes will
generally cause table updates to run more quickly—in some
cases by a much as 20 to 30 percent faster than updates on
tables where USING HASH was not used in
creating primary and unique keys. This is due to the fact that
less memory is required (because no ordered indexes are
created), and that less CPU must be utilized (because fewer
indexes must be read and possibly updated). However, it also
means that queries that could otherwise use range scans must be
satisfied by other means, which can result in slower selects.
When calculating Cluster memory requirements, you may find
useful the ndb_size.pl utility which is
available in recent MySQL 5.5 releases. This Perl
script connects to a current (non-Cluster) MySQL database and
creates a report on how much space that database would require
if it used the NDBCLUSTER storage
engine. For more information, see
Section 16.4.21, “ndb_size.pl — NDBCLUSTER Size Requirement Estimator”.
It is especially important to keep in mind that every
MySQL Cluster table must have a primary key. The
NDB storage engine creates a
primary key automatically if none is defined; this primary key
is created without USING HASH.
There is no easy way to determine exactly how much memory is
being used for storage of Cluster indexes at any given time;
however, warnings are written to the Cluster log when 80% of
available DataMemory or
IndexMemory is in use, and again when use
reaches 85%, 90%, and so on.
B.10.11: What file systems can I use with MySQL Cluster? What about network file systems or network shares?
Generally, any file system that is native to the host operating system should work well with MySQL Cluster. If you find that a given file system works particularly well (or not so especially well) with MySQL Cluster, we invite you to discuss your findings in the MySQL Cluster Forums.
For Windows, we recommend that you use NTFS
file systems for MySQL Cluster, just as we do for standard
MySQL. We do not test MySQL Cluster with FAT
or VFAT file systems. Because of this, we do
not recommend their use with MySQL or MySQL Cluster.
MySQL Cluster is implemented as a shared-nothing solution; the idea behind this is that the failure of a single piece of hardware should not cause the failure of multiple cluster nodes, or possibly even the failure of the cluster as a whole. For this reason, the use of network shares or network file systems is not supported for MySQL Cluster. This also applies to shared storage devices such as SANs.
B.10.12: Can I run MySQL Cluster nodes inside virtual machines (such as those created by VMWare, Parallels, or Xen)?
This is possible but not recommended for a production environment.
We have found that running MySQL Cluster processes inside a virtual machine can give rise to issues with timing and disk subsystems that have a strong negative impact on the operation of the cluster. The behavior of the cluster is often unpredictable in these cases.
If an issue can be reproduced outside the virtual environment, then we may be able to provide assistance. Otherwise, we cannot support it at this time.
B.10.13:
I am trying to populate a MySQL Cluster database. The loading
process terminates prematurely and I get an error message like
this one:
ERROR 1114: The table 'my_cluster_table' is
full
Why is this happening?
The cause is very likely to be that your setup does not provide
sufficient RAM for all table data and all indexes,
including the primary key required by the
NDB storage engine and
automatically created in the event that the table definition
does not include the definition of a primary key.
It is also worth noting that all data nodes should have the same amount of RAM, since no data node in a cluster can use more memory than the least amount available to any individual data node. For example, if there are four computers hosting Cluster data nodes, and three of these have 3GB of RAM available to store Cluster data while the remaining data node has only 1GB RAM, then each data node can devote at most 1GB to MySQL Cluster data and indexes.
In some cases it is possible to get Table is
full errors in MySQL client applications even when
ndb_mgm -e "ALL REPORT MEMORYUSAGE" shows
significant free
DataMemory. You can
force NDB to create extra
partitions for MySQL Cluster tables and thus have more memory
available for hash indexes by using the
MAX_ROWS option for
CREATE TABLE. In general, setting
MAX_ROWS to twice the number of rows that you
expect to store in the table should be sufficient.
For similar reasons, you can also sometimes encounter problems
with data node restarts on nodes that are heavily loaded with
data. In MySQL Cluster NDB 7.1 and MySQL Cluster NDB 7.2, the
addition of the
MinFreePct parameter
helps with this issue.
B.10.14: MySQL Cluster uses TCP/IP. Does this mean that I can run it over the Internet, with one or more nodes in remote locations?
It is very unlikely that a cluster would perform reliably under such conditions, as MySQL Cluster was designed and implemented with the assumption that it would be run under conditions guaranteeing dedicated high-speed connectivity such as that found in a LAN setting using 100 Mbps or gigabit Ethernet—preferably the latter. We neither test nor warrant its performance using anything slower than this.
Also, it is extremely important to keep in mind that communications between the nodes in a MySQL Cluster are not secure; they are neither encrypted nor safeguarded by any other protective mechanism. The most secure configuration for a cluster is in a private network behind a firewall, with no direct access to any Cluster data or management nodes from outside. (For SQL nodes, you should take the same precautions as you would with any other instance of the MySQL server.) For more information, see Section 16.5.10, “MySQL Cluster Security Issues”.
B.10.15: Do I have to learn a new programming or query language to use MySQL Cluster?
No. Although some specialized commands are used to manage and configure the cluster itself, only standard (My)SQL statements are required for the following operations:
Creating, altering, and dropping tables
Inserting, updating, and deleting table data
Creating, changing, and dropping primary and unique indexes
Some specialized configuration parameters and files are required to set up a MySQL Cluster—see Section 16.3.2, “MySQL Cluster Configuration Files”, for information about these.
A few simple commands are used in the MySQL Cluster management client (ndb_mgm) for tasks such as starting and stopping cluster nodes. See Section 16.5.2, “Commands in the MySQL Cluster Management Client”.
B.10.16: How do I find out what an error or warning message means when using MySQL Cluster?
There are two ways in which this can be done:
From within the mysql client, use SHOW ERRORS or SHOW WARNINGS immediately upon being notified of the error or warning condition.
From a system shell prompt, use perror --ndb
error_code.
B.10.17: Is MySQL Cluster transaction-safe? What isolation levels are supported?
Yes. For tables created with the
NDB storage engine, transactions
are supported. Currently, MySQL Cluster supports only the
READ COMMITTED transaction
isolation level.
B.10.18: What storage engines are supported by MySQL Cluster?
Clustering with MySQL is supported only by the
NDB storage engine. That is, in
order for a table to be shared between nodes in a MySQL Cluster,
the table must be created using ENGINE=NDB
(or the equivalent option ENGINE=NDBCLUSTER).
It is possible to create tables using other storage engines
(such as MyISAM or
InnoDB) on a MySQL server being
used with a MySQL Cluster, but these
non-NDB tables do
not participate in clustering; each such
table is strictly local to the individual MySQL server instance
on which it is created.
B.10.19: In the event of a catastrophic failure—say, for instance, the whole city loses power and my UPS fails—would I lose all my data?
All committed transactions are logged. Therefore, although it is possible that some data could be lost in the event of a catastrophe, this should be quite limited. Data loss can be further reduced by minimizing the number of operations per transaction. (It is not a good idea to perform large numbers of operations per transaction in any case.)
B.10.20:
Is it possible to use FULLTEXT indexes with
MySQL Cluster?
FULLTEXT indexing is not supported by any
storage engine other than MyISAM.
We are working to add this capability to MySQL Cluster tables in
a future release.
B.10.21: Can I run multiple nodes on a single computer?
It is possible but not always advisable. One of the chief reasons to run a cluster is to provide redundancy. To obtain the full benefits of this redundancy, each node should reside on a separate machine. If you place multiple nodes on a single machine and that machine fails, you lose all of those nodes. For this reason, if you do run multiple data nodes on a single machine, it is extremely important that they be set up in such a way that the failure of this machine does not cause the loss of all the data nodes in a given node group.
Given that MySQL Cluster can be run on commodity hardware loaded with a low-cost (or even no-cost) operating system, the expense of an extra machine or two is well worth it to safeguard mission-critical data. It also worth noting that the requirements for a cluster host running a management node are minimal. This task can be accomplished with a 300 MHz Pentium or equivalent CPU and sufficient RAM for the operating system, plus a small amount of overhead for the ndb_mgmd and ndb_mgm processes.
It is acceptable to run multiple cluster data nodes on a single host that has multiple CPUs, cores, or both. Beginning with MySQL Cluster NDB 6.4, there is also a special multi-threaded version of the data node binary intended for use on such systems. For more information, see Section 16.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”.
It is also possible in some cases to run data nodes and SQL nodes concurrently on the same machine; how well such an arrangement performs is dependent on a number of factors such as number of cores and CPUs as well as the amount of disk and memory available to the data node and SQL node processes, and you must take these factors into account when planning such a configuration.
B.10.22: Are there any limitations that I should be aware of when using MySQL Cluster?
Limitations on NDB tables in MySQL
NDB 6.x and MySQL Cluster NDB 7.x include the following:
Temporary tables are not supported; a
CREATE TEMPORARY TABLEstatement usingENGINE=NDBorENGINE=NDBCLUSTERfails with an error.The only types of user-defined partitioning supported for
NDBCLUSTERtables areKEYandLINEAR KEY. (Beginning with MySQL 5.1.12, attempting to create anNDBtable using any other partitioning type fails with an error.)FULLTEXTindexes are not supported.Index prefixes are not supported. Only complete columns may be indexed.
Spatial indexes are not supported (although spatial columns can be used). See Section 11.17, “Spatial Extensions”.
Prior to MySQL Cluster NDB 6.3.19, the
NDBCLUSTERstorage engine did not support partial transactions or partial rollbacks of transactions. Beginning with MySQL Cluster NDB 6.3.19, this limitation has been removed, and the behavior ofNDBCLUSTERis now in line with that of other transactional storage engines (such asInnoDB) that can roll back individual statements.Prior to MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4, the maximum number of attributes allowed per table was 128; beginning with MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4, this limit is increased to 512. Attribute names cannot be any longer than 31 characters. For each table, the maximum combined length of the table and database names is 122 characters.
The maximum size for a table row is 8 kilobytes, not counting
BLOBvalues. There is no set limit for the number of rows per table. Table size limits depend on a number of factors, in particular on the amount of RAM available to each data node.The
NDBCLUSTERengine does not support foreign key constraints. As withMyISAMtables, if these are specified in aCREATE TABLEorALTER TABLEstatement, they are ignored.
For a complete listing of limitations in MySQL Cluster, see Section 16.1.6, “Known Limitations of MySQL Cluster”. For information about limitations in MySQL Cluster 5.1 that are lifted in MySQL 5.5, MySQL Cluster NDB 6.x, or MySQL Cluster NDB 7.0, see Section 16.1.6.11, “Previous MySQL Cluster Issues Resolved in MySQL 5.1, MySQL Cluster NDB 6.x, and MySQL Cluster NDB 7.x”.
B.10.23: How do I import an existing MySQL database into a MySQL Cluster?
You can import databases into MySQL Cluster much as you would
with any other version of MySQL. Other than the limitations
mentioned elsewhere in this FAQ, the only other special
requirement is that any tables to be included in the cluster
must use the NDB storage engine.
This means that the tables must be created with
ENGINE=NDB or
ENGINE=NDBCLUSTER.
It is also possible to convert existing tables that use other
storage engines to NDBCLUSTER using
one or more ALTER TABLE
statement. However, the definition of the table must be
compatible with the NDBCLUSTER
storage engine prior to making the conversion. In MySQL
5.5, an additional workaround is also required; see
Section 16.1.6, “Known Limitations of MySQL Cluster”, for details.
B.10.24: How do MySQL Cluster nodes communicate with one another?
Cluster nodes can communicate through any of three different transport mechanisms: TCP/IP, SHM (shared memory), and SCI (Scalable Coherent Interface). Where available, SHM is used by default between nodes residing on the same cluster host; however, this is considered experimental. SCI is a high-speed (1 gigabit per second and higher), high-availability protocol used in building scalable multi-processor systems; it requires special hardware and drivers. See Section 16.3.5, “Using High-Speed Interconnects with MySQL Cluster”, for more about using SCI as a transport mechanism for MySQL Cluster.
B.10.25: What is an arbitrator?
If one or more data nodes in a cluster fail, it is possible that not all cluster data nodes will be able to “see” one another. In fact, it is possible that two sets of data nodes might become isolated from one another in a network partitioning, also known as a “split-brain” scenario. This type of situation is undesirable because each set of data nodes tries to behave as though it is the entire cluster. An arbitrator is required to decide between the competing sets of data nodes.
When all data nodes in at least one node group are alive,
network partitioning is not an issue, because no single subset
of the cluster can form a functional cluster on its own. The
real problem arises when no single node group has all its nodes
alive, in which case network partitioning (the
“split-brain” scenario) becomes possible. Then an
arbitrator is required. All cluster nodes recognize the same
node as the arbitrator, which is normally the management server;
however, it is possible to configure any of the MySQL Servers in
the cluster to act as the arbitrator instead. The arbitrator
accepts the first set of cluster nodes to contact it, and tells
the remaining set to shut down. Arbitrator selection is
controlled by the ArbitrationRank
configuration parameter for MySQL Server and management server
nodes. In MySQL Cluster NDB 7.0.7 and later, you can also use
the ArbitrationRank configuration parameter
to control the arbitrator selection process. For more
information about these parameters, see
Section 16.3.2.5, “Defining a MySQL Cluster Management Server”.
The role of arbitrator does not in and of itself impose any heavy demands upon the host so designated, and thus the arbitrator host does not need to be particularly fast or to have extra memory especially for this purpose.
B.10.26: What data types are supported by MySQL Cluster?
MySQL Cluster NDB 6.x and later releases support all of the
usual MySQL data types, including those associated with
MySQL's spatial extensions; however, the
NDB storage engine does not support
spatial indexes. (Spatial indexes are supported only by
MyISAM; see
Section 11.17, “Spatial Extensions”, for more information.) In
addition, there are some differences with regard to indexes when
used with NDB tables.
MySQL Cluster Disk Data tables (that is, tables created with
TABLESPACE ... STORAGE DISK ENGINE=NDB or
TABLESPACE ... STORAGE DISK
ENGINE=NDBCLUSTER) have only fixed-width rows. This
means that (for example) each Disk Data table record
containing a
VARCHAR(255)
column requires space for 255 characters (as required for the
character set and collation being used for the table),
regardless of the actual number of characters stored therein.
See Section 16.1.6, “Known Limitations of MySQL Cluster”, for more information about these issues.
B.10.27: How do I start and stop MySQL Cluster?
It is necessary to start each node in the cluster separately, in the following order:
Start the management node, using the ndb_mgmd command.
You must include the
-for--config-fileoption to tell the management node where its configuration file can be found.Start each data node with the ndbd command.
Each data node must be started with the
-cor--connect-stringoption so that the data node knows how to connect to the management server.Start each MySQL Server (SQL node) using your preferred startup script, such as mysqld_safe.
Each MySQL Server must be started with the
--ndbclusterand--ndb-connectstringoptions. These options cause mysqld to enableNDBCLUSTERstorage engine support and how to connect to the management server.
Each of these commands must be run from a system shell on the
machine housing the affected node. (You do not have to be
physically present at the machine—a remote login shell can
be used for this purpose.) You can verify that the cluster is
running by starting the NDB
management client ndb_mgm on the machine
housing the management node and issuing the
SHOW or ALL STATUS
command.
To shut down a running cluster, issue the command
SHUTDOWN in the management client.
Alternatively, you may enter the following command in a system
shell:
shell> ndb_mgm -e "SHUTDOWN"
(The quotation marks in this example are optional, since there
are no spaces in the command string following the
-e option; in addition, the
SHUTDOWN command, like other management
client commands, is not case-sensitive.)
Either of these commands causes the ndb_mgm, ndb_mgm, and any ndbd processes to terminate gracefully. MySQL servers running as SQL nodes can be stopped using mysqladmin shutdown.
For more information, see Section 16.5.2, “Commands in the MySQL Cluster Management Client”, and Section 16.2.6, “Safe Shutdown and Restart of MySQL Cluster”.
B.10.28: What happens to MySQL Cluster data when the MySQL Cluster is shut down?
The data that was held in memory by the cluster's data nodes is written to disk, and is reloaded into memory the next time that the cluster is started.
B.10.29: Is it a good idea to have more than one management node for a MySQL Cluster?
It can be helpful as a fail-safe. Only one management node controls the cluster at any given time, but it is possible to configure one management node as primary, and one or more additional management nodes to take over in the event that the primary management node fails.
See Section 16.3.2, “MySQL Cluster Configuration Files”, for information on how to configure MySQL Cluster management nodes.
B.10.30: Can I mix different kinds of hardware and operating systems in one MySQL Cluster?
Yes, as long as all machines and operating systems have the same “endianness” (all big-endian or all little-endian). We are working to overcome this limitation in a future MySQL Cluster release.
It is also possible to use software from different MySQL Cluster releases on different nodes. However, we support this only as part of a rolling upgrade procedure (see Section 16.5.4, “Performing a Rolling Restart of a MySQL Cluster”).
B.10.31: Can I run two data nodes on a single host? Two SQL nodes?
Yes, it is possible to do this. In the case of multiple data nodes, it is advisable (but not required) for each node to use a different data directory. If you want to run multiple SQL nodes on one machine, each instance of mysqld must use a different TCP/IP port. However, in MySQL 5.5, running more than one cluster node of a given type per machine is generally not encouraged or supported for production use.
We also advise against running data nodes and SQL nodes together on the same host, since the ndbd and mysqld processes may compete for memory.
B.10.32: Can I use host names with MySQL Cluster?
Yes, it is possible to use DNS and DHCP for cluster hosts. However, if your application requires “five nines” availability, you should use fixed (numeric) IP addresses, since making communication between Cluster hosts dependent on services such as DNS and DHCP introduces additional potential points of failure.
B.10.33: Does MySQL Cluster support IPv6?
IPv6 is supported for connections between SQL nodes (MySQL servers), but connections between all other types of MySQL Cluster nodes must use IPv4.
In practical terms, this means that you can use IPv6 for replication between MySQL Clusters, but connections between nodes in the same MySQL Cluster must use IPv4. For more information, see Section 16.6.3, “Known Issues in MySQL Cluster Replication”.
B.10.34: How do I handle MySQL users in a MySQL Cluster having multiple MySQL servers?
MySQL user accounts and privileges are normally not automatically propagated between different MySQL servers accessing the same MySQL Cluster. MySQL Cluster NDB 7.2.1 and later provide support for distributed privileges. While privilege distribution is not enabled automatically, you can activate it by following a procedure provided in the MySQL Cluster documentation. See Section 16.5.13, “Distributed MySQL Privileges for MySQL Cluster”, for more information.
B.10.35: How do I continue to send queries in the event that one of the SQL nodes fails?
MySQL Cluster does not provide any sort of automatic failover between SQL nodes. Your application must be prepared to handlethe loss of SQL nodes and to fail over between them.
B.10.36: How do I back up and restore a MySQL Cluster?
You can use the NDB native backup and restore functionality in the MySQL Cluster management client and the ndb_restore program. See Section 16.5.3, “Online Backup of MySQL Cluster”, and Section 16.4.17, “ndb_restore — Restore a MySQL Cluster Backup”.
You can also use the traditional functionality provided for this purpose in mysqldump and the MySQL server. See Section 4.5.4, “mysqldump — A Database Backup Program”, for more information.
B.10.37: What is an “angel process”?
This process monitors and, if necessary, attempts to restart the data node process. If you check the list of active processes on your system after starting ndbd, you can see that there are actually 2 processes running by that name, as shown here (we omit the output from ndb_mgmd and ndbd for brevity):
shell>./ndb_mgmdshell>ps aux | grep ndbme 23002 0.0 0.0 122948 3104 ? Ssl 14:14 0:00 ./ndb_mgmd me 23025 0.0 0.0 5284 820 pts/2 S+ 14:14 0:00 grep ndb shell>./ndbd -c 127.0.0.1 --initialshell>ps aux | grep ndbme 23002 0.0 0.0 123080 3356 ? Ssl 14:14 0:00 ./ndb_mgmd me 23096 0.0 0.0 35876 2036 ? Ss 14:14 0:00 ./ndbd -c 127.0.0.1 --initial me 23097 1.0 2.4 524116 91096 ? Sl 14:14 0:00 ./ndbd -c 127.0.0.1 --initial me 23168 0.0 0.0 5284 812 pts/2 R+ 14:15 0:00 grep ndb
The ndbd process showing 0 memory and CPU
usage is the angel process. It actually does use a very small
amount of each, of course. It simply checks to see if the main
ndbd process (the primary data node process
that actually handles the data) is running. If permitted to do
so (for example, if the StopOnError
configuration parameter is set to false—see
Section 16.3.3.1, “MySQL Cluster Data Node Configuration Parameters”), the angel process
tries to restart the primary data node process.
This set of Frequently Asked Questions derives from the experience of MySQL's Support and Development groups in handling many inquiries about CJK (Chinese-Japanese-Korean) issues.
Questions
B.11.1: What CJK character sets are available in MySQL?
B.11.2: I have inserted CJK characters into my table. Why does
SELECTdisplay them as “?” characters?B.11.3: What problems should I be aware of when working with the Big5 Chinese character set?
B.11.4: Why do Japanese character set conversions fail?
B.11.5: What should I do if I want to convert SJIS
81CAtocp932?B.11.6: How does MySQL represent the Yen (
¥) sign?B.11.7: Does MySQL plan to make a separate character set where
5Cis the Yen sign, as at least one other major DBMS does?B.11.8: Of what issues should I be aware when working with Korean character sets in MySQL?
B.11.9: Why do I get Incorrect string value error messages?
B.11.10: Why does my GUI front end or browser not display CJK characters correctly in my application using Access, PHP, or another API?
B.11.11: I've upgraded to MySQL 5.5. How can I revert to behavior like that in MySQL 4.0 with regard to character sets?
B.11.12: Why do some
LIKEandFULLTEXTsearches with CJK characters fail?B.11.13: How do I know whether character
Xis available in all character sets?B.11.14: Why do CJK strings sort incorrectly in Unicode? (I)
B.11.15: Why do CJK strings sort incorrectly in Unicode? (II)
B.11.16: Why are my supplementary characters rejected by MySQL?
B.11.17: Shouldn't it be “CJKV”?
B.11.18: Does MySQL allow CJK characters to be used in database and table names?
B.11.19: Where can I find translations of the MySQL Manual into Chinese, Japanese, and Korean?
B.11.20: Where can I get help with CJK and related issues in MySQL?
Questions and Answers
B.11.1: What CJK character sets are available in MySQL?
The list of CJK character sets may vary depending on your MySQL
version. For example, the eucjpms character
set was not supported prior to MySQL 5.0.3 (see
Changes in MySQL 5.0.3). However, since the name of the
applicable language appears in the
DESCRIPTION column for every entry in the
INFORMATION_SCHEMA.CHARACTER_SETS
table, you can obtain a current list of all the non-Unicode CJK
character sets using this query:
mysql>SELECT CHARACTER_SET_NAME, DESCRIPTION->FROM INFORMATION_SCHEMA.CHARACTER_SETS->WHERE DESCRIPTION LIKE '%Chinese%'->OR DESCRIPTION LIKE '%Japanese%'->OR DESCRIPTION LIKE '%Korean%'->ORDER BY CHARACTER_SET_NAME;+--------------------+---------------------------+ | CHARACTER_SET_NAME | DESCRIPTION | +--------------------+---------------------------+ | big5 | Big5 Traditional Chinese | | cp932 | SJIS for Windows Japanese | | eucjpms | UJIS for Windows Japanese | | euckr | EUC-KR Korean | | gb2312 | GB2312 Simplified Chinese | | gbk | GBK Simplified Chinese | | sjis | Shift-JIS Japanese | | ujis | EUC-JP Japanese | +--------------------+---------------------------+ 8 rows in set (0.01 sec)
(See Section 19.1, “The INFORMATION_SCHEMA CHARACTER_SETS Table”, for more
information.)
MySQL supports the two common variants of the
GB (Guojia
Biaozhun, or National
Standard, or Simplified Chinese)
character sets which are official in the People's Republic of
China: gb2312 and gbk.
Sometimes people try to insert gbk characters
into gb2312, and it works most of the time
because gbk is a superset of
gb2312—but eventually they try to
insert a rarer Chinese character and it doesn't work. (See Bug
#16072 for an example).
Here, we try to clarify exactly what characters are legitimate
in gb2312 or gbk, with
reference to the official documents. Please check these
references before reporting gb2312 or
gbk bugs.
For a complete listing of the
gb2312characters, ordered according to thegb2312_chinese_cicollation: gb2312MySQL's
gbkis in reality “Microsoft code page 936”. This differs from the officialgbkfor charactersA1A4(middle dot),A1AA(em dash),A6E0-A6F5, andA8BB-A8C0.For a listing of
gbk/Unicode mappings, see http://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP936.TXT.For MySQL's listing of
gbkcharacters, see gbk.
B.11.2:
I have inserted CJK characters into my table. Why does
SELECT display them as
“?” characters?
This problem is usually due to a setting in MySQL that doesn't match the settings for the application program or the operating system. Here are some common steps for correcting these types of issues:
Be certain of what MySQL version you are using.
Use the statement
SELECT VERSION();to determine this.Make sure that the database is actually using the desired character set.
People often think that the client character set is always the same as either the server character set or the character set used for display purposes. However, both of these are false assumptions. You can make sure by checking the result of
SHOW CREATE TABLEor—better yet—by using this statement:tablenameSELECT character_set_name, collation_name FROM information_schema.columns WHERE table_schema = your_database_name AND table_name = your_table_name AND column_name = your_column_name;Determine the hexadecimal value of the character or characters that are not being displayed correctly.
You can obtain this information for a column
column_namein the tabletable_nameusing the following query:SELECT HEX(
column_name) FROMtable_name;3Fis the encoding for the?character; this means that?is the character actually stored in the column. This most often happens because of a problem converting a particular character from your client character set to the target character set.Make sure that a round trip possible—that is, when you select
literal(or_introducer hexadecimal-value), you obtainliteralas a result.For example, the Japanese Katakana character Pe (
ペ') exists in all CJK character sets, and has the code point value (hexadecimal coding)0x30da. To test a round trip for this character, use this query:SELECT 'ペ' AS `ペ`; /* or SELECT _ucs2 0x30da; */
If the result is not also
ペ, then the round trip has failed.For bug reports regarding such failures, we might ask you to follow up with
SELECT HEX('ペ');. Then we can determine whether the client encoding is correct.Make sure that the problem is not with the browser or other application, rather than with MySQL.
Use the mysql client program (on Windows: mysql.exe) to accomplish this task. If mysql displays correctly but your application doesn't, then your problem is probably due to system settings.
To find out what your settings are, use the
SHOW VARIABLESstatement, whose output should resemble what is shown here:mysql>
SHOW VARIABLES LIKE 'char%';+--------------------------+----------------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/mysql/charsets/ | +--------------------------+----------------------------------------+ 8 rows in set (0.03 sec)These are typical character-set settings for an international-oriented client (notice the use of
utf8Unicode) connected to a server in the West (latin1is a West Europe character set and a default for MySQL).Although Unicode (usually the
utf8variant on Unix, and theucs2variant on Windows) is preferable to Latin, it is often not what your operating system utilities support best. Many Windows users find that a Microsoft character set, such ascp932for Japanese Windows, is suitable.If you cannot control the server settings, and you have no idea what your underlying computer is, then try changing to a common character set for the country that you're in (
euckr= Korea;gb2312orgbk= People's Republic of China;big5= Taiwan;sjis,ujis,cp932, oreucjpms= Japan;ucs2orutf8= anywhere). Usually it is necessary to change only the client and connection and results settings. There is a simple statement which changes all three at once:SET NAMES. For example:SET NAMES 'big5';
Once the setting is correct, you can make it permanent by editing
my.cnformy.ini. For example you might add lines looking like these:[mysqld] character-set-server=big5 [client] default-character-set=big5
It is also possible that there are issues with the API configuration setting being used in your application; see Why does my GUI front end or browser not display CJK characters correctly...? for more information.
B.11.3: What problems should I be aware of when working with the Big5 Chinese character set?
MySQL supports the Big5 character set which is common in Hong
Kong and Taiwan (Republic of China). MySQL's
big5 is in reality Microsoft code page 950,
which is very similar to the original big5
character set. We changed to this
character set starting with MySQL version 4.1.16 / 5.0.16 (as a
result of Bug #12476). For example, the following statements
work in current versions of MySQL, but not in old versions:
mysql>CREATE TABLE big5 (BIG5 CHAR(1) CHARACTER SET BIG5);Query OK, 0 rows affected (0.13 sec) mysql>INSERT INTO big5 VALUES (0xf9dc);Query OK, 1 row affected (0.00 sec) mysql>SELECT * FROM big5;+------+ | big5 | +------+ | 嫺 | +------+ 1 row in set (0.02 sec)
A feature request for adding HKSCS extensions
has been filed. People who need this extension may find the
suggested patch for Bug #13577 to be of interest.
B.11.4: Why do Japanese character set conversions fail?
MySQL supports the sjis,
ujis, cp932, and
eucjpms character sets, as well as Unicode. A
common need is to convert between character sets. For example,
there might be a Unix server (typically with
sjis or ujis) and a
Windows client (typically with cp932).
In the following conversion table, the ucs2
column represents the source, and the sjis,
cp932, ujis, and
eucjpms columns represent the
destinations—that is, the last 4 columns provide the
hexadecimal result when we use
CONVERT(ucs2) or we assign a
ucs2 column containing the value to an
sjis, cp932,
ujis, or eucjpms column.
| Character Name | ucs2 | sjis | cp932 | ujis | eucjpms |
|---|---|---|---|---|---|
| BROKEN BAR | 00A6 | 3F | 3F | 8FA2C3 | 3F |
| FULLWIDTH BROKEN BAR | FFE4 | 3F | FA55 | 3F | 8FA2 |
| YEN SIGN | 00A5 | 3F | 3F | 20 | 3F |
| FULLWIDTH YEN SIGN | FFE5 | 818F | 818F | A1EF | 3F |
| TILDE | 007E | 7E | 7E | 7E | 7E |
| OVERLINE | 203E | 3F | 3F | 20 | 3F |
| HORIZONTAL BAR | 2015 | 815C | 815C | A1BD | A1BD |
| EM DASH | 2014 | 3F | 3F | 3F | 3F |
| REVERSE SOLIDUS | 005C | 815F | 5C | 5C | 5C |
| FULLWIDTH "" | FF3C | 3F | 815F | 3F | A1C0 |
| WAVE DASH | 301C | 8160 | 3F | A1C1 | 3F |
| FULLWIDTH TILDE | FF5E | 3F | 8160 | 3F | A1C1 |
| DOUBLE VERTICAL LINE | 2016 | 8161 | 3F | A1C2 | 3F |
| PARALLEL TO | 2225 | 3F | 8161 | 3F | A1C2 |
| MINUS SIGN | 2212 | 817C | 3F | A1DD | 3F |
| FULLWIDTH HYPHEN-MINUS | FF0D | 3F | 817C | 3F | A1DD |
| CENT SIGN | 00A2 | 8191 | 3F | A1F1 | 3F |
| FULLWIDTH CENT SIGN | FFE0 | 3F | 8191 | 3F | A1F1 |
| POUND SIGN | 00A3 | 8192 | 3F | A1F2 | 3F |
| FULLWIDTH POUND SIGN | FFE1 | 3F | 8192 | 3F | A1F2 |
| NOT SIGN | 00AC | 81CA | 3F | A2CC | 3F |
| FULLWIDTH NOT SIGN | FFE2 | 3F | 81CA | 3F | A2CC |
Now consider the following portion of the table.
| ucs2 | sjis | cp932 | |
|---|---|---|---|
| NOT SIGN | 00AC | 81CA | 3F |
| FULLWIDTH NOT SIGN | FFE2 | 3F | 81CA |
This means that MySQL converts the NOT SIGN
(Unicode U+00AC) to sjis
code point 0x81CA and to
cp932 code point 3F.
(3F is the question mark
(“?”)—this is what is always used when the
conversion cannot be performed.
B.11.5:
What should I do if I want to convert SJIS
81CA to cp932?
Our answer is: “?”. There are serious complaints
about this: many people would prefer a “loose”
conversion, so that 81CA (NOT SIGN) in
sjis becomes 81CA (FULLWIDTH NOT
SIGN) in cp932. We are considering
a change to this behavior.
B.11.6:
How does MySQL represent the Yen (¥) sign?
A problem arises because some versions of Japanese character
sets (both sjis and euc)
treat 5C as a reverse
solidus (\—also known as a
backslash), and others treat it as a yen sign
(¥).
MySQL follows only one version of the JIS (Japanese Industrial
Standards) standard description. In MySQL,
5C is always the reverse solidus
(\).
B.11.7:
Does MySQL plan to make a separate character set where
5C is the Yen sign, as at least one other
major DBMS does?
This is one possible solution to the Yen sign issue; however, this will not happen in MySQL 5.1 or 6.0.
B.11.8: Of what issues should I be aware when working with Korean character sets in MySQL?
In theory, while there have been several versions of the
euckr (Extended Unix Code
Korea) character set, only one problem has been
noted.
We use the “ASCII” variant of EUC-KR, in which the
code point 0x5c is REVERSE SOLIDUS, that is
\, instead of the “KS-Roman”
variant of EUC-KR, in which the code point
0x5c is WON
SIGN(₩). This means that you
cannot convert Unicode U+20A9 to
euckr:
mysql>SELECT->CONVERT('₩' USING euckr) AS euckr,->HEX(CONVERT('₩' USING euckr)) AS hexeuckr;+-------+----------+ | euckr | hexeuckr | +-------+----------+ | ? | 3F | +-------+----------+ 1 row in set (0.00 sec)
MySQL's graphic Korean chart is here: euckr.
B.11.9: Why do I get Incorrect string value error messages?
For illustration, we'll create a table with one Unicode
(ucs2) column and one Chinese
(gb2312) column.
mysql>CREATE TABLE ch->(ucs2 CHAR(3) CHARACTER SET ucs2,->gb2312 CHAR(3) CHARACTER SET gb2312);Query OK, 0 rows affected (0.05 sec)
We'll try to place the rare character 汌 in
both columns.
mysql> INSERT INTO ch VALUES ('A汌B','A汌B');
Query OK, 1 row affected, 1 warning (0.00 sec)
Ah, there is a warning. Use the following statement to see what it is:
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Warning
Code: 1366
Message: Incorrect string value: '\xE6\xB1\x8CB' for column 'gb2312' at row 1
1 row in set (0.00 sec)
So it is a warning about the gb2312 column
only.
mysql> SELECT ucs2,HEX(ucs2),gb2312,HEX(gb2312) FROM ch; +-------+--------------+--------+-------------+ | ucs2 | HEX(ucs2) | gb2312 | HEX(gb2312) | +-------+--------------+--------+-------------+ | A汌B | 00416C4C0042 | A?B | 413F42 | +-------+--------------+--------+-------------+ 1 row in set (0.00 sec)
Several things need explanation here:
The fact that it is a “warning” rather than an “error” is characteristic of MySQL. We like to try to do what we can, to get the best fit, rather than give up.
The
汌character is not in thegb2312character set. We described that problem earlier.If you are using an old version of MySQL, you will probably see a different message.
With
sql_mode=TRADITIONAL, there would be an error message, rather than a warning.
B.11.10: Why does my GUI front end or browser not display CJK characters correctly in my application using Access, PHP, or another API?
Obtain a direct connection to the server using the
mysql client (Windows:
mysql.exe), and try the same query there. If
mysql responds correctly, then the trouble
may be that your application interface requires initialization.
Use mysql to tell you what character set or
sets it uses with the statement SHOW VARIABLES LIKE
'char%';. If you are using Access, then you are most
likely connecting with Connector/ODBC. In this case, you should
check Section 21.1.4, “Connector/ODBC Configuration”. If, for
instance, you use big5, you would enter
SET NAMES 'big5'. (Note that no
; is required in this case). If you are using
ASP, you might need to add SET NAMES in the
code. Here is an example that has worked in the past:
<%
Session.CodePage=0
Dim strConnection
Dim Conn
strConnection="driver={MySQL ODBC 3.51 Driver};server=server;uid=username;" \
& "pwd=password;database=database;stmt=SET NAMES 'big5';"
Set Conn = Server.CreateObject("ADODB.Connection")
Conn.Open strConnection
%>
In much the same way, if you are using any character set other
than latin1 with Connector/Net, then you must
specify the character set in the connection string. See
Section 21.2.5.1, “Connecting to MySQL Using Connector/Net”, for more
information.
If you are using PHP, try this:
<?php
$link = mysql_connect($host, $usr, $pwd);
mysql_select_db($db);
if( mysql_error() ) { print "Database ERROR: " . mysql_error(); }
mysql_query("SET NAMES 'utf8'", $link);
?>
In this case, we used SET NAMES to change
character_set_client and
character_set_connection and
character_set_results.
We encourage the use of the newer mysqli
extension, rather than mysql. Using
mysqli, the previous example could be
rewritten as shown here:
<?php
$link = new mysqli($host, $usr, $pwd, $db);
if( mysqli_connect_errno() )
{
printf("Connect failed: %s\n", mysqli_connect_error());
exit();
}
$link->query("SET NAMES 'utf8'");
?>
Another issue often encountered in PHP applications has to do
with assumptions made by the browser. Sometimes adding or
changing a <meta> tag suffices to
correct the problem: for example, to insure that the user agent
interprets page content as UTF-8, you should
include <meta http-equiv="Content-Type"
content="text/html; charset=utf-8"> in the
<head> of the HTML page.
If you are using Connector/J, see Section 21.3.5.4, “Using Character Sets and Unicode”.
B.11.11: I've upgraded to MySQL 5.5. How can I revert to behavior like that in MySQL 4.0 with regard to character sets?
In MySQL Version 4.0, there was a single “global” character set for both server and client, and the decision as to which character to use was made by the server administrator. This changed starting with MySQL Version 4.1. What happens now is a “handshake”, as described in Section 9.1.4, “Connection Character Sets and Collations”:
When a client connects, it sends to the server the name of the character set that it wants to use. The server uses the name to set the
character_set_client,character_set_results, andcharacter_set_connectionsystem variables. In effect, the server performs aSET NAMESoperation using the character set name.
The effect of this is that you cannot control the client
character set by starting mysqld with
--character-set-server=utf8.
However, some of our Asian customers have said that they prefer
the MySQL 4.0 behavior. To make it possible to retain this
behavior, we added a mysqld switch,
--character-set-client-handshake,
which can be turned off with
--skip-character-set-client-handshake.
If you start mysqld with
--skip-character-set-client-handshake,
then, when a client connects, it sends to the server the name of
the character set that it wants to use—however,
the server ignores this request from the
client.
By way of example, suppose that your favorite server character
set is latin1 (unlikely in a CJK area, but
this is the default value). Suppose further that the client uses
utf8 because this is what the client's
operating system supports. Now, start the server with
latin1 as its default character set:
mysqld --character-set-server=latin1
And then start the client with the default character set
utf8:
mysql --default-character-set=utf8
The current settings can be seen by viewing the output of
SHOW VARIABLES:
mysql> SHOW VARIABLES LIKE 'char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
8 rows in set (0.01 sec)
Now stop the client, and then stop the server using mysqladmin. Then start the server again, but this time tell it to skip the handshake like so:
mysqld --character-set-server=utf8 --skip-character-set-client-handshake
Start the client with utf8 once again as the
default character set, then display the current settings:
mysql> SHOW VARIABLES LIKE 'char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
8 rows in set (0.01 sec)
As you can see by comparing the differing results from
SHOW VARIABLES, the server
ignores the client's initial settings if the
--skip-character-set-client-handshake
is used.
B.11.12:
Why do some LIKE and
FULLTEXT searches with CJK characters fail?
There is a very simple problem with
LIKE searches on
BINARY and
BLOB columns: we need to know the
end of a character. With multi-byte character sets, different
characters might have different octet lengths. For example, in
utf8, A requires one byte
but ペ requires three bytes, as shown here:
+-------------------------+---------------------------+ | OCTET_LENGTH(_utf8 'A') | OCTET_LENGTH(_utf8 'ペ') | +-------------------------+---------------------------+ | 1 | 3 | +-------------------------+---------------------------+ 1 row in set (0.00 sec)
If we don't know where the first character ends, then we don't
know where the second character begins, in which case even very
simple searches such as LIKE
'_A%' fail. The solution is to use a regular CJK
character set in the first place, or to convert to a CJK
character set before comparing.
This is one reason why MySQL cannot allow encodings of nonexistent characters. If it is not strict about rejecting bad input, then it has no way of knowing where characters end.
For FULLTEXT searches, we need to know where
words begin and end. With Western languages, this is rarely a
problem because most (if not all) of these use an
easy-to-identify word boundary—the space character.
However, this is not usually the case with Asian writing. We
could use arbitrary halfway measures, like assuming that all Han
characters represent words, or (for Japanese) depending on
changes from Katakana to Hiragana due to grammatical endings.
However, the only sure solution requires a comprehensive word
list, which means that we would have to include a dictionary in
the server for each Asian language supported. This is simply not
feasible.
B.11.13:
How do I know whether character X is
available in all character sets?
The majority of simplified Chinese and basic nonhalfwidth
Japanese Kana characters appear
in all CJK character sets. This stored procedure accepts a
UCS-2 Unicode character, converts it to all
other character sets, and displays the results in hexadecimal.
DELIMITER //
CREATE PROCEDURE p_convert(ucs2_char CHAR(1) CHARACTER SET ucs2)
BEGIN
CREATE TABLE tj
(ucs2 CHAR(1) character set ucs2,
utf8 CHAR(1) character set utf8,
big5 CHAR(1) character set big5,
cp932 CHAR(1) character set cp932,
eucjpms CHAR(1) character set eucjpms,
euckr CHAR(1) character set euckr,
gb2312 CHAR(1) character set gb2312,
gbk CHAR(1) character set gbk,
sjis CHAR(1) character set sjis,
ujis CHAR(1) character set ujis);
INSERT INTO tj (ucs2) VALUES (ucs2_char);
UPDATE tj SET utf8=ucs2,
big5=ucs2,
cp932=ucs2,
eucjpms=ucs2,
euckr=ucs2,
gb2312=ucs2,
gbk=ucs2,
sjis=ucs2,
ujis=ucs2;
/* If there is a conversion problem, UPDATE will produce a warning. */
SELECT hex(ucs2) AS ucs2,
hex(utf8) AS utf8,
hex(big5) AS big5,
hex(cp932) AS cp932,
hex(eucjpms) AS eucjpms,
hex(euckr) AS euckr,
hex(gb2312) AS gb2312,
hex(gbk) AS gbk,
hex(sjis) AS sjis,
hex(ujis) AS ujis
FROM tj;
DROP TABLE tj;
END//
The input can be any single ucs2 character,
or it can be the code point value (hexadecimal representation)
of that character. For example, from Unicode's list of
ucs2 encodings and names
(http://www.unicode.org/Public/UNIDATA/UnicodeData.txt),
we know that the Katakana
character Pe appears in all CJK
character sets, and that its code point value is
0x30da. If we use this value as the argument
to p_convert(), the result is as shown here:
mysql> CALL p_convert(0x30da)//
+------+--------+------+-------+---------+-------+--------+------+------+------+
| ucs2 | utf8 | big5 | cp932 | eucjpms | euckr | gb2312 | gbk | sjis | ujis |
+------+--------+------+-------+---------+-------+--------+------+------+------+
| 30DA | E3839A | C772 | 8379 | A5DA | ABDA | A5DA | A5DA | 8379 | A5DA |
+------+--------+------+-------+---------+-------+--------+------+------+------+
1 row in set (0.04 sec)
Since none of the column values is
3F—that is, the question mark character
(?)—we know that every conversion
worked.
B.11.14: Why do CJK strings sort incorrectly in Unicode? (I)
Sometimes people observe that the result of a
utf8_unicode_ci or
ucs2_unicode_ci search, or of an
ORDER BY sort is not what they think a native
would expect. Although we never rule out the possibility that
there is a bug, we have found in the past that many people do
not read correctly the standard table of weights for the Unicode
Collation Algorithm. MySQL uses the table found at
http://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt.
This is not the first table you will find by navigating from the
unicode.org home page, because MySQL uses the
older 4.0.0 “allkeys” table, rather than the more
recent 4.1.0 table. (The newer '520'
collations in MySQL 5.6 use the 5.2 “allkeys”
table.) This is because we are very wary about changing ordering
which affects indexes, lest we bring about situations such as
that reported in Bug #16526, illustrated as follows:
mysql<CREATE TABLE tj (s1 CHAR(1) CHARACTER SET utf8 COLLATE utf8_unicode_ci);Query OK, 0 rows affected (0.05 sec) mysql>INSERT INTO tj VALUES ('が'),('か');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM tj WHERE s1 = 'か';+------+ | s1 | +------+ | が | | か | +------+ 2 rows in set (0.00 sec)
The character in the first result row is not the one that we
searched for. Why did MySQL retrieve it? First we look for the
Unicode code point value, which is possible by reading the
hexadecimal number for the ucs2 version of
the characters:
mysql> SELECT s1, HEX(CONVERT(s1 USING ucs2)) FROM tj;
+------+-----------------------------+
| s1 | HEX(CONVERT(s1 USING ucs2)) |
+------+-----------------------------+
| が | 304C |
| か | 304B |
+------+-----------------------------+
2 rows in set (0.03 sec)
Now we search for 304B and
304C in the 4.0.0 allkeys
table, and find these lines:
304B ; [.1E57.0020.000E.304B] # HIRAGANA LETTER KA 304C ; [.1E57.0020.000E.304B][.0000.0140.0002.3099] # HIRAGANA LETTER GA; QQCM
The official Unicode names (following the “#” mark)
tell us the Japanese syllabary (Hiragana), the informal
classification (letter, digit, or punctuation mark), and the
Western identifier (KA or
GA, which happen to be voiced and unvoiced
components of the same letter pair). More importantly, the
primary weight (the first hexadecimal
number inside the square brackets) is 1E57 on
both lines. For comparisons in both searching and sorting, MySQL
pays attention to the primary weight only, ignoring all the
other numbers. This means that we are sorting
が and か correctly
according to the Unicode specification. If we wanted to
distinguish them, we'd have to use a non-UCA (Unicode Collation
Algorithm) collation (utf8_bin or
utf8_general_ci), or to compare the
HEX() values, or use
ORDER BY CONVERT(s1 USING sjis). Being
correct “according to Unicode” isn't enough, of
course: the person who submitted the bug was equally correct. We
plan to add another collation for Japanese according to the JIS
X 4061 standard, in which voiced/unvoiced letter pairs like
KA/GA are distinguishable
for ordering purposes.
B.11.15: Why do CJK strings sort incorrectly in Unicode? (II)
If you are using Unicode (ucs2 or
utf8), and you know what the Unicode sort
order is (see Section B.11, “MySQL 5.5 FAQ: MySQL Chinese, Japanese, and Korean
Character Sets”), but MySQL still seems
to sort your table incorrectly, then you should first verify the
table character set:
mysql> SHOW CREATE TABLE t\G
******************** 1. row ******************
Table: t
Create Table: CREATE TABLE `t` (
`s1` char(1) CHARACTER SET ucs2 DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Since the character set appears to be correct, let's see what
information the
INFORMATION_SCHEMA.COLUMNS table
can provide about this column:
mysql>SELECT COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME->FROM INFORMATION_SCHEMA.COLUMNS->WHERE COLUMN_NAME = 's1'->AND TABLE_NAME = 't';+-------------+--------------------+-----------------+ | COLUMN_NAME | CHARACTER_SET_NAME | COLLATION_NAME | +-------------+--------------------+-----------------+ | s1 | ucs2 | ucs2_general_ci | +-------------+--------------------+-----------------+ 1 row in set (0.01 sec)
(See Section 19.4, “The INFORMATION_SCHEMA COLUMNS Table”, for more information.)
You can see that the collation is
ucs2_general_ci instead of
ucs2_unicode_ci. The reason why this is so
can be found using SHOW CHARSET, as shown
here:
mysql> SHOW CHARSET LIKE 'ucs2%';
+---------+---------------+-------------------+--------+
| Charset | Описание | Default collation | Maxlen |
+---------+---------------+-------------------+--------+
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
+---------+---------------+-------------------+--------+
1 row in set (0.00 sec)
For ucs2 and utf8, the
default collation is “general”. To specify a
Unicode collation, use COLLATE
ucs2_unicode_ci.
B.11.16: Why are my supplementary characters rejected by MySQL?
Before MySQL 5.5.3, MySQL does not support supplementary
characters—that is, characters which need more than 3
bytes—for UTF-8. We support only what
Unicode calls the Basic Multilingual Plane / Plane
0. Only a few very rare Han characters are
supplementary; support for them is uncommon. This has led to
reports such as that found in Bug #12600, which we rejected as
“not a bug”. With utf8, we must
truncate an input string when we encounter bytes that we don't
understand. Otherwise, we wouldn't know how long the bad
multi-byte character is.
One possible workaround is to use ucs2
instead of utf8, in which case the
“bad” characters are changed to question marks;
however, no truncation takes place. You can also change the data
type to BLOB or
BINARY, which perform no validity
checking.
As of MySQL 5.5.3, Unicode support is extended to include
supplementary characters by means of additional Unicode
character sets: utf16,
utf32, and 4-byte utf8mb4.
These character sets support supplementary Unicode characters
outside the Basic Multilingual Plane (BMP).
B.11.17: Shouldn't it be “CJKV”?
No. The term “CJKV” (Chinese Japanese Korean Vietnamese) refers to Vietnamese character sets which contain Han (originally Chinese) characters. MySQL has no plan to support the old Vietnamese script using Han characters. MySQL does of course support the modern Vietnamese script with Western characters.
As of MySQL 5.6, there are Vietnamese collations for Unicode character sets, as described in Section 9.1.14.1, “Unicode Character Sets”.
B.11.18: Does MySQL allow CJK characters to be used in database and table names?
This issue is fixed in MySQL 5.1, by automatically rewriting the names of the corresponding directories and files.
For example, if you create a database named
楮 on a server whose operating system does
not support CJK in directory names, MySQL creates a directory
named @0w@00a5@00ae. which is just a fancy
way of encoding E6A5AE—that is, the
Unicode hexadecimal representation for the
楮 character. However, if you run a
SHOW DATABASES statement, you can
see that the database is listed as 楮.
B.11.19: Where can I find translations of the MySQL Manual into Chinese, Japanese, and Korean?
A Simplified Chinese version of the Manual, current for MySQL 5.1.12, can be found at http://dev.mysql.com/doc/. The Japanese translation of the MySQL 4.1 manual can be downloaded from http://dev.mysql.com/doc/.
B.11.20: Where can I get help with CJK and related issues in MySQL?
The following resources are available:
A listing of MySQL user groups can be found at http://dev.mysql.com/user-groups/.
View feature requests relating to character set issues at http://tinyurl.com/y6xcuf.
Visit the MySQL Character Sets, Collation, Unicode Forum. We are also in the process of adding foreign-language forums at http://forums.mysql.com/.
For common questions, issues, and answers relating to the MySQL Connectors and other APIs, see the following areas of the Manual:
In the following section, we provide answers to questions that are most frequently asked about MySQL Replication.
Questions
B.13.1: Must the slave be connected to the master all the time?
B.13.2: Must I enable networking on my master and slave to enable replication?
B.13.3: How do I know how late a slave is compared to the master? In other words, how do I know the date of the last statement replicated by the slave?
B.13.4: How do I force the master to block updates until the slave catches up?
B.13.5: What issues should I be aware of when setting up two-way replication?
B.13.6: How can I use replication to improve performance of my system?
B.13.7: What should I do to prepare client code in my own applications to use performance-enhancing replication?
B.13.8: When and how much can MySQL replication improve the performance of my system?
B.13.9: How can I use replication to provide redundancy or high availability?
B.13.10: How do I tell whether a master server is using statement-based or row-based binary logging format?
B.13.11: How do I tell a slave to use row-based replication?
B.13.12: How do I prevent
GRANTandREVOKEstatements from replicating to slave machines?B.13.13: Does replication work on mixed operating systems (for example, the master runs on Linux while slaves run on Mac OS X and Windows)?
B.13.14: Does replication work on mixed hardware architectures (for example, the master runs on a 64-bit machine while slaves run on 32-bit machines)?
Questions and Answers
B.13.1: Must the slave be connected to the master all the time?
No, it does not. The slave can go down or stay disconnected for hours or even days, and then reconnect and catch up on updates. For example, you can set up a master/slave relationship over a dial-up link where the link is up only sporadically and for short periods of time. The implication of this is that, at any given time, the slave is not guaranteed to be in synchrony with the master unless you take some special measures.
To ensure that catchup can occur for a slave that has been disconnected, you must not remove binary log files from the master that contain information that has not yet been replicated to the slaves. Asynchronous replication can work only if the slave is able to continue reading the binary log from the point where it last read events.
B.13.2: Must I enable networking on my master and slave to enable replication?
Yes, networking must be enabled on the master and slave. If
networking is not enabled, the slave cannot connect to the
master and transfer the binary log. Check that the
skip-networking option has not
been enabled in the configuration file for either server.
B.13.3: How do I know how late a slave is compared to the master? In other words, how do I know the date of the last statement replicated by the slave?
Check the Seconds_Behind_Master column in the
output from SHOW SLAVE STATUS.
See Section 15.1.4.1, “Checking Replication Status”.
When the slave SQL thread executes an event read from the
master, it modifies its own time to the event timestamp. (This
is why TIMESTAMP is well
replicated.) In the Time column in the output
of SHOW PROCESSLIST, the number
of seconds displayed for the slave SQL thread is the number of
seconds between the timestamp of the last replicated event and
the real time of the slave machine. You can use this to
determine the date of the last replicated event. Note that if
your slave has been disconnected from the master for one hour,
and then reconnects, you may immediately see large
Time values such as 3600 for the slave SQL
thread in SHOW PROCESSLIST. This
is because the slave is executing statements that are one hour
old. See Section 15.2.1, “Replication Implementation Details”.
B.13.4: How do I force the master to block updates until the slave catches up?
Use the following procedure:
On the master, execute these statements:
mysql>
FLUSH TABLES WITH READ LOCK;mysql>SHOW MASTER STATUS;Record the replication coordinates (the current binary log file name and position) from the output of the
SHOWstatement.On the slave, issue the following statement, where the arguments to the
MASTER_POS_WAIT()function are the replication coordinate values obtained in the previous step:mysql>
SELECT MASTER_POS_WAIT('log_name',log_pos);The
SELECTstatement blocks until the slave reaches the specified log file and position. At that point, the slave is in synchrony with the master and the statement returns.On the master, issue the following statement to enable the master to begin processing updates again:
mysql>
UNLOCK TABLES;
B.13.5: What issues should I be aware of when setting up two-way replication?
MySQL replication currently does not support any locking protocol between master and slave to guarantee the atomicity of a distributed (cross-server) update. In other words, it is possible for client A to make an update to co-master 1, and in the meantime, before it propagates to co-master 2, client B could make an update to co-master 2 that makes the update of client A work differently than it did on co-master 1. Thus, when the update of client A makes it to co-master 2, it produces tables that are different from what you have on co-master 1, even after all the updates from co-master 2 have also propagated. This means that you should not chain two servers together in a two-way replication relationship unless you are sure that your updates can safely happen in any order, or unless you take care of mis-ordered updates somehow in the client code.
You should also realize that two-way replication actually does not improve performance very much (if at all) as far as updates are concerned. Each server must do the same number of updates, just as you would have a single server do. The only difference is that there is a little less lock contention because the updates originating on another server are serialized in one slave thread. Even this benefit might be offset by network delays.
B.13.6: How can I use replication to improve performance of my system?
Set up one server as the master and direct all writes to it.
Then configure as many slaves as you have the budget and
rackspace for, and distribute the reads among the master and the
slaves. You can also start the slaves with the
--skip-innodb,
--low-priority-updates, and
--delay-key-write=ALL options to
get speed improvements on the slave end. In this case, the slave
uses nontransactional MyISAM tables instead
of InnoDB tables to get more speed by
eliminating transactional overhead.
B.13.7: What should I do to prepare client code in my own applications to use performance-enhancing replication?
See the guide to using replication as a scale-out solution, Section 15.3.3, “Using Replication for Scale-Out”.
B.13.8: When and how much can MySQL replication improve the performance of my system?
MySQL replication is most beneficial for a system that processes frequent reads and infrequent writes. In theory, by using a single-master/multiple-slave setup, you can scale the system by adding more slaves until you either run out of network bandwidth, or your update load grows to the point that the master cannot handle it.
To determine how many slaves you can use before the added
benefits begin to level out, and how much you can improve
performance of your site, you must know your query patterns, and
determine empirically by benchmarking the relationship between
the throughput for reads and writes on a typical master and a
typical slave. The example here shows a rather simplified
calculation of what you can get with replication for a
hypothetical system. Let reads and
writes denote the number of reads and writes
per second, respectively.
Let's say that system load consists of 10% writes and 90% reads,
and we have determined by benchmarking that
reads is 1200 - 2 *
writes. In other words, the system can do
1,200 reads per second with no writes, the average write is
twice as slow as the average read, and the relationship is
linear. Suppose that the master and each slave have the same
capacity, and that we have one master and
N slaves. Then we have for each
server (master or slave):
reads = 1200 - 2 * writes
reads = 9 * writes /
(N + 1) (reads are split, but writes
replicated to all slaves)
9 * writes / (N +
1) + 2 * writes = 1200
writes = 1200 / (2 +
9/(N + 1))
The last equation indicates the maximum number of writes for
N slaves, given a maximum possible
read rate of 1,200 per minute and a ratio of nine reads per
write.
This analysis yields the following conclusions:
If
N= 0 (which means we have no replication), our system can handle about 1200/11 = 109 writes per second.If
N= 1, we get up to 184 writes per second.If
N= 8, we get up to 400 writes per second.If
N= 17, we get up to 480 writes per second.Eventually, as
Napproaches infinity (and our budget negative infinity), we can get very close to 600 writes per second, increasing system throughput about 5.5 times. However, with only eight servers, we increase it nearly four times.
Note that these computations assume infinite network bandwidth
and neglect several other factors that could be significant on
your system. In many cases, you may not be able to perform a
computation similar to the one just shown that accurately
predicts what will happen on your system if you add
N replication slaves. However,
answering the following questions should help you decide whether
and by how much replication will improve the performance of your
system:
What is the read/write ratio on your system?
How much more write load can one server handle if you reduce the reads?
For how many slaves do you have bandwidth available on your network?
B.13.9: How can I use replication to provide redundancy or high availability?
How you implement redundancy is entirely dependent on your application and circumstances. High-availability solutions (with automatic failover) require active monitoring and either custom scripts or third party tools to provide the failover support from the original MySQL server to the slave.
To handle the process manually, you should be able to switch from a failed master to a pre-configured slave by altering your application to talk to the new server or by adjusting the DNS for the MySQL server from the failed server to the new server.
For more information and some example solutions, see Section 15.3.6, “Switching Masters During Failover”.
B.13.10: How do I tell whether a master server is using statement-based or row-based binary logging format?
Check the value of the
binlog_format system variable:
mysql> SHOW VARIABLES LIKE 'binlog_format';
The value shown will be one of STATEMENT,
ROW, or MIXED. For
MIXED mode, row-based logging is preferred
but replication switches automatically to statement-based
logging under certain conditions; for information about when
this may occur, see Section 5.2.4.3, “Mixed Binary Logging Format”.
B.13.11: How do I tell a slave to use row-based replication?
Slaves automatically know which format to use.
B.13.12:
How do I prevent GRANT and
REVOKE statements from
replicating to slave machines?
Start the server with the
--replicate-wild-ignore-table=mysql.%
option to ignore replication for tables in the
mysql database.
B.13.13: Does replication work on mixed operating systems (for example, the master runs on Linux while slaves run on Mac OS X and Windows)?
Yes.
B.13.14: Does replication work on mixed hardware architectures (for example, the master runs on a 64-bit machine while slaves run on 32-bit machines)?
Yes.
- B.14.1. Distributed Replicated Block Device (DRBD)
- B.14.2. Linux Heartbeat
- B.14.3. DRBD Architecture
- B.14.4. DRBD and MySQL Replication
- B.14.5. DRBD and File Systems
- B.14.6. DRBD and LVM
- B.14.7. DRBD and Virtualization
- B.14.8. DRBD and Security
- B.14.9. DRBD and System Requirements
- B.14.10. DRBD and Support and Consulting
In the following section, we provide answers to questions that are most frequently asked about Distributed Replicated Block Device (DRBD).
Questions
Questions and Answers
DRBD is an acronym for Distributed Replicated Block Device. DRBD is an open source Linux kernel block device which leverages synchronous replication to achieve a consistent view of data between two systems, typically an Active and Passive system. DRBD currently supports all the major flavors of Linux and comes bundled in several major Linux distributions. The DRBD project is maintained by LINBIT.
B.14.1.2: What are “Block Devices”?
A block device is the type of device used to represent storage in the Linux Kernel. All physical disk devices present a block device interface. Additionally, virtual disk systems like LVM or DRBD present a block device interface. In this way, the file system or other software that might want to access a disk device can be used with any number of real or virtual devices without having to know anything about their underlying implementation details.
B.14.1.3: How is DRBD licensed?
DRBD is licensed under the GPL.
B.14.1.4: Where can I download DRBD?
Please see http://www.drbd.org/download/packages/.
B.14.1.5: If I find a bug in DRBD, to whom do I submit the issue?
Bug reports should be submitted to the DRBD mailing list. Please see http://lists.linbit.com/.
B.14.1.6: Where can I get more technical and business information concerning MySQL and DRBD?
Please visit http://mysql.com/drbd/.
In the following section, we provide answers to questions that are most frequently asked about Linux Heartbeat.
Questions
Questions and Answers
B.14.2.1: How is Linux Heartbeat licensed?
Linux Heartbeat is licensed under the GPL.
B.14.2.2: Where can I download Linux Heartbeat?
Please see http://linux-ha.org/download/index.html.
B.14.2.3: If I find a bug with Linux Heartbeat, to whom do I submit the issue?
Bug reports should be submitted to http://www.linux-ha.org/ClusterResourceManager/BugReports.
In the following section, we provide answers to questions that are most frequently asked about DRBD Architecture.
Questions
B.14.3.1: Is an Active/Active option available for MySQL with DRBD?
B.14.3.2: What MySQL storage engines are supported with DRBD?
B.14.3.3: How long does a failover take?
B.14.3.4: How long does it take to resynchronize data after a failure?
B.14.3.5: Are there any situations where you shouldn't use DRBD?
B.14.3.6: Are there any limitations to DRBD?
B.14.3.7: Where can I find more information on sample architectures?
Questions and Answers
B.14.3.1: Is an Active/Active option available for MySQL with DRBD?
Currently, MySQL does not support Active/Active configurations using DRBD “out of the box”.
B.14.3.2: What MySQL storage engines are supported with DRBD?
All of the MySQL transactional storage engines are supported by DRBD, including InnoDB and Falcon. For archived or read-only data, MyISAM or Archive can also be used.
B.14.3.3: How long does a failover take?
Failover time is dependent on many things, some of which are configurable. After activating the passive host, MySQL will have to start and run a normal recovery process. If the InnoDB log files have been configured to a large size and there was heavy write traffic, this may take a reasonably long period of time. However, under normal circumstances, failover tends to take less than a minute.
B.14.3.4: How long does it take to resynchronize data after a failure?
Resynchronization time depends on how long the two machines are out of communication and how much data was written during that period of time. Resynchronization time is a function of data to be synced, network speed and disk speed. DRBD maintains a bitmap of changed blocks on the primary machine, so only those blocks that have changed will need to be transferred.
B.14.3.5: Are there any situations where you shouldn't use DRBD?
See When Not To Use DRBD.
B.14.3.6: Are there any limitations to DRBD?
See DRBD limitations (or are they?).
B.14.3.7: Where can I find more information on sample architectures?
For an example of a Heartbeat R1-compatible resource configuration involving a MySQL database backed by DRBD, see DRBD User's Guide.
For an example of the same DRBD-backed configuration for a MySQL database in a Heartbeat CRM cluster, see DRBD User's Guide.
In the following section, we provide answers to questions that are most frequently asked about MySQL Replication Scale-out.
Questions
Questions and Answers
B.14.4.1: What is the difference between MySQL Cluster and DRBD?
Both MySQL Cluster and DRBD replicate data synchronously. MySQL Cluster leverages a shared-nothing storage architecture in which the cluster can be architected beyond an Active/Passive configuration. DRBD operates at a much lower level within the “stack”, at the disk I/O level. For a comparison of various high availability features between these two options, please refer to Глава 14, High Availability and Scalability.
B.14.4.2: What is the difference between MySQL Replication and DRBD?
MySQL Replication replicates data asynchronously while DRBD replicates data synchronously. Also, MySQL Replication replicates MySQL statements, while DRBD replicates the underlying block device that stores the MySQL data files. For a comparison of various high availability features between these two options, please refer to the high availability comparison grid, Глава 14, High Availability and Scalability.
B.14.4.3: How can I combine MySQL Replication scale-out with DRBD?
MySQL Replication is typically deployed in a Master to many Slaves configuration. In this configuration, having many Slaves provides read scalability. DRBD is used to provide high-availability for the Master MySQL Server in an Active/Passive configuration. This provides for automatic failover, safeguards against data loss, and automatically synchronizes the failed MySQL Master after a failover.
The most likely scenario in which MySQL Replication scale-out can be leveraged with DRBD is in the form of attaching replicated MySQL “read-slaves” off of the Active-Master MySQL Server. Since DRBD replicates an entire block device, master information such as the binary logs are also replicated. In this way, all of the slaves can attach to the Virtual IP Address managed by Linux Heartbeat. In the event of a failure, the asynchronous nature of MySQL Replication allows the slaves to continue with the new Active machine as their master with no intervention needed.
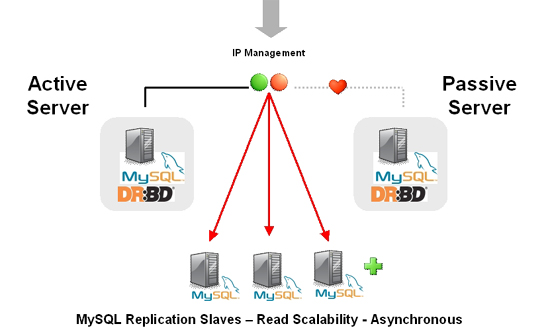
In the following section, we provide answers to questions that are most frequently asked about DRBD and file systems.
Questions
B.14.5.1: Can XFS be used with DRBD?
Questions and Answers
B.14.5.1: Can XFS be used with DRBD?
Yes. XFS uses dynamic block size, thus DRBD 0.7 or later is needed.
In the following section, we provide answers to questions that are most frequently asked about DRBD and LVM.
Questions
Questions and Answers
B.14.6.1: Can I use DRBD on top of LVM?
Yes, DRBD supports on-line resizing. If you enlarge your logical volume that acts as a backing device for DRBD, you can enlarge DRBD itself too, and of course your file system if it supports resizing.
B.14.6.2: Can I use LVM on top of DRBD?
Yes, you can use DRBD as a Physical Volume (PV) for LVM.
Depending on the default LVM configuration shipped with your
distribution, you may need to add the
/dev/drbd* device files to the
filter option in your
lvm.conf so LVM scans your DRBDs for PV
signatures.
B.14.6.3: Can I use DRBD on top of LVM while at the same time running LVM on top of that DRBD?
This requires careful tuning of your LVM configuration to avoid duplicate PV scans, but yes, it is possible.
In the following section, we provide answers to questions that are most frequently asked about DRBD and virtualization.
Questions
Questions and Answers
B.14.7.1: Can I use DRBD with OpenVZ?
See http://wiki.openvz.org/HA_cluster_with_DRBD_and_Heartbeat.
B.14.7.2: Can I use DRBD with Xen or KVM?
Yes. If you are looking for professional consultancy or expert commercial support for Xen- or KVM-based virtualization clusters with DRBD, contact LINBIT (http://www.linbit.com).
In the following section, we provide answers to questions that are most frequently asked about DRBD and security.
Questions
Questions and Answers
B.14.8.1: Can I encrypt/compress the exchanged data?
Yes. But there is no option within DRBD to allow for this. You’ll need to leverage a VPN and the network layer should do the rest.
B.14.8.2: Does DRBD do mutual node authentication?
Yes, starting with DRBD 8 shared-secret mutual node authentication is supported.
In the following section, we provide answers to questions that are most frequently asked about DRBD and System Requirements.
Questions
Questions and Answers
B.14.9.1: What other packages besides DRBD are required?
When using pre-built binary packages, none except a matching
kernel, plus packages for glibc and your
favorite shell. When compiling DRBD from source additional
prerequisite packages may be required. They include but are not
limited to:
glib-devel
openssl
devel
libgcrypt-devel
glib2-devel
pkgconfig
ncurses-devel
rpm-build
rpm-devel
redhat-rpm-config
gcc
gcc-c++
bison
flex
gnutls-devel
lm_sensors-devel
net-snmp-devel
python-devel
bzip2-devel
libselinux-devel
perl-DBI
libnet
Pre-built x86 and x86_64 packages for specific kernel versions are available with a support subscription from LINBIT. Please note that if the kernel is upgraded, DRBD must be as well.
B.14.9.2: How many machines are required to set up DRBD?
Two machines are required to achieve the minimum degree of high availability. Although at any one given point in time one will be primary and one will be secondary, it is better to consider the machines as part of a mirrored pair without a “natural” primary machine.
B.14.9.3: Does DRBD only run on Linux?
DRBD is a Linux Kernel Module, and can work with many popular Linux distributions. DRBD is currently not available for non-Linux operating systems.
In the following section, we provide answers to questions that are most frequently asked about DRBD and resources.
Questions
B.14.10.1: Does MySQL offer professional consulting to help with designing a DRBD system?
B.14.10.2: Does MySQL offer support for DRBD and Linux Heartbeat from MySQL?
B.14.10.3: Are pre-built binaries or RPMs available?
B.14.10.4: Does MySQL have documentation to help me with the installation and configuration of DRBD and Linux Heartbeat?
B.14.10.5: Is there a dedicated discussion forum for MySQL High-Availability?
B.14.10.6: Where can I get more information about MySQL for DRBD?
Questions and Answers
B.14.10.1: Does MySQL offer professional consulting to help with designing a DRBD system?
Yes. MySQL offers consulting for the design, installation, configuration, and monitoring of high availability DRBD. For more information concerning a High Availability Jumpstart, please see: http://www.mysql.com/consulting/packaged/scaleout.html.
B.14.10.2: Does MySQL offer support for DRBD and Linux Heartbeat from MySQL?
Yes. Support for DRBD is available with an add-on subscription to MySQL Enterprise called “DRBD for MySQL”. For more information about support options for DRBD see: http://mysql.com/products/enterprise/features.html.
For the list of supported Linux distributions, please see: http://www.mysql.com/support/supportedplatforms/enterprise.html.
DRBD is only available on Linux. DRBD is not available on Windows, MacOS, Solaris, HPUX, AIX, FreeBSD, or other non-Linux platforms.
B.14.10.3: Are pre-built binaries or RPMs available?
Yes. “DRBD for MySQL” is an add-on subscription to MySQL Enterprise, which provides pre-built binaries for DRBD. For more information, see: http://mysql.com/products/enterprise/features.html.
B.14.10.4: Does MySQL have documentation to help me with the installation and configuration of DRBD and Linux Heartbeat?
For MySQL-specific DRBD documentation, see Section 14.2, “Using MySQL with DRBD”.
For general DRBD documentation, see DRBD User's Guide.
B.14.10.5: Is there a dedicated discussion forum for MySQL High-Availability?
Yes, http://forums.mysql.com/list.php?144.
B.14.10.6: Where can I get more information about MySQL for DRBD?
For more information about MySQL for DRBD, including a technical white paper please see: http://www.mysql.com/products/enterprise/drbd.html.